데이터 파이프라인 자세히 알아보기
아래 내용은 도서 빅데이터를 지탱하는 기술에서 발췌했습니다.
빅데이터의 특징
- “여러 컴퓨터에 분산처리한다.”
Hadoop, NoSQL의 등장 배경
- 인터넷이 보급되면서 Relational DB로는 처리가 불가능한 대량의 데이터가 축적되었다. 이에 따른 새로운 저장 시스템, 처리 엔진이 필요했다.
Hadoop, Spark
-
Hadoop: 다수의 컴퓨터에서 대량의 데이터를 처리하기 위해 등장- Distributed Storage System (분산 시스템)
- 데이터 분산 저장, 분산 처리
- 빅데이터를 빠르게 처리할 수 있는 시스템
- 방대한 스토리지, 데이터를 순차적으로 처리할 수 있는 구조
- 보통 단일 솔루션이 아닌 Hadoop Ecosystem을 지칭함
- HDFS, MapReduce, YARN 등
- 구글의 분산 처리 프레임워크
MapReduce를 참고하여 제작 -
Hive: 초기 Hadoop은 자바로 프로그래밍 해야했었던 한계점을 극복, SQL과 같은 쿼리 언어를 Hadoop에서 실행하기 위한 소프트웨어
- Distributed Storage System (분산 시스템)
-
Spark: 빅데이터 분석 환경에서 Real Time data 를 프로세싱하기 더 최적화- Hadoop의 진화된 버전
- Hadoop의 MapReduce는 작업물을 디스크인 hdfs에 저장해야 하는데, Spark는 RDD라는 분산 메모리에 저장
- 빠르고, 쉽고, 활용 범위 넓음
- 다양한 언어 지원 - Java, Python을 통해 API 제공
- SQL Query 환경 역시 서포트
- Hadoop의 진화된 버전
NoSQL
-
NoSQL: RDB의 제약을 제거, 빈번한 읽기/쓰기와 분산처리가 강점- NoSQL의 다양한 종류
- key-value store (KVS): 다수의 키와 값을 관련지어 저장
- e.g.) Redis
- document store: JSON과 같은 복잡한 데이터 구조를 저장
- e.g.) MongoDB
- wide-column store: 여러 키를 사용하여 높은 확장성을 제공
- e.g.) Cassandra
- key-value store (KVS): 다수의 키와 값을 관련지어 저장
- NoSQL의 다양한 종류
- 둘을 조합해 NoSQL 데이터베이스에 기록하고, Hadoop으로 분산처리
Data warehouse와 Hadoop의 공존
- Data warehouse: 대량의 데이터를 장기 보존하는 것에 최적화되어 있다.
- 계속 데이터가 증가하면서 기업의 전통적인 data warehouse의 규모가 커졌다. 이 부하를 줄이기 위해 Hadoop을 사용하기 시작했다.
- 데이터 처리는 Hadoop에게 맡기고, 중요한 혹은 작은 데이터만 data warehouse에 저장하는 등 사용을 구분하기 시작했다.
데이터 파이프라인 (Data Pipeline)
데이터를 한 장소에서 다른 장소로 차례대로 전달하는, 데이터로 구성된 일련의 시스템
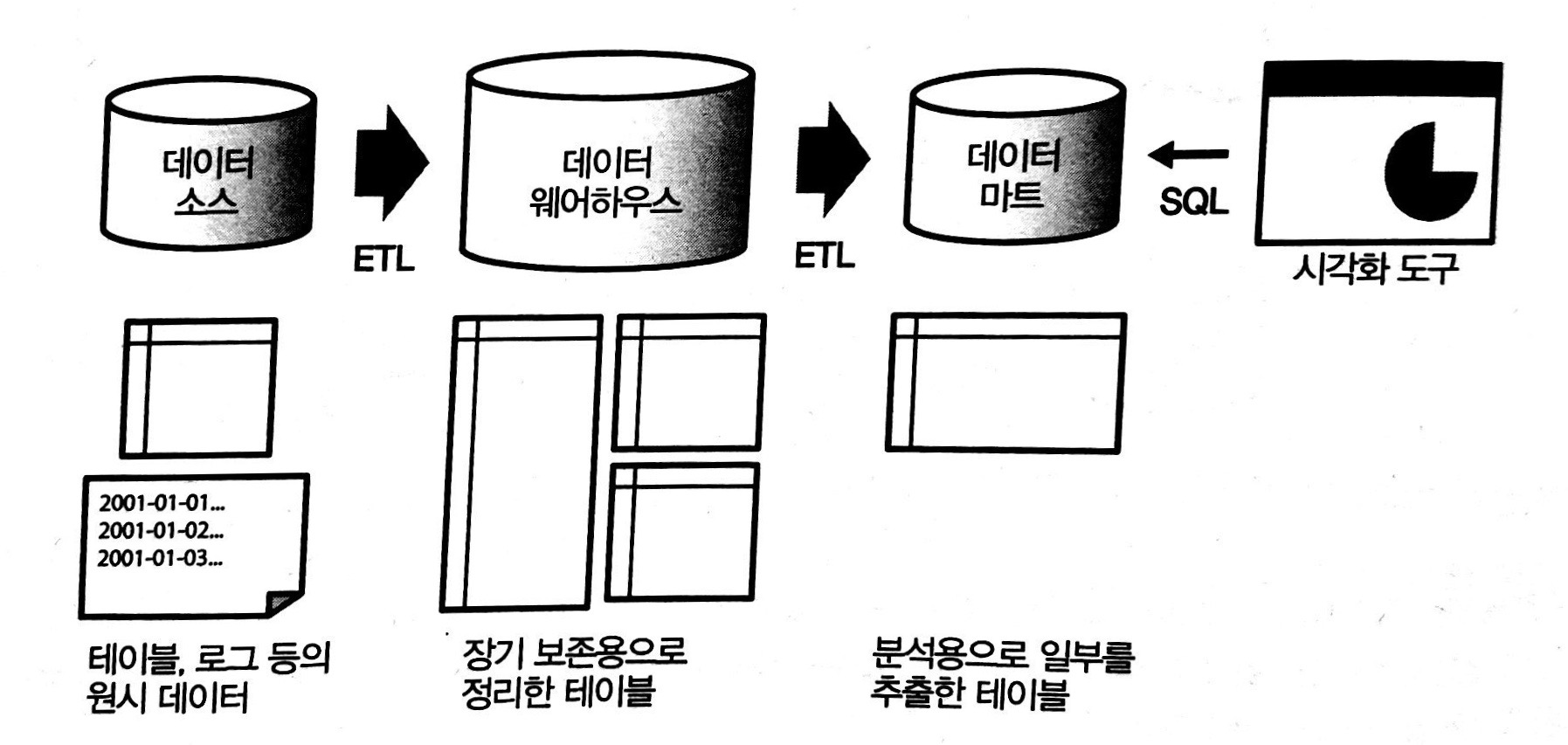
- 데이터 마트: 데이터 웨어하우스에서 필요한 데이터만을 추출해 구축
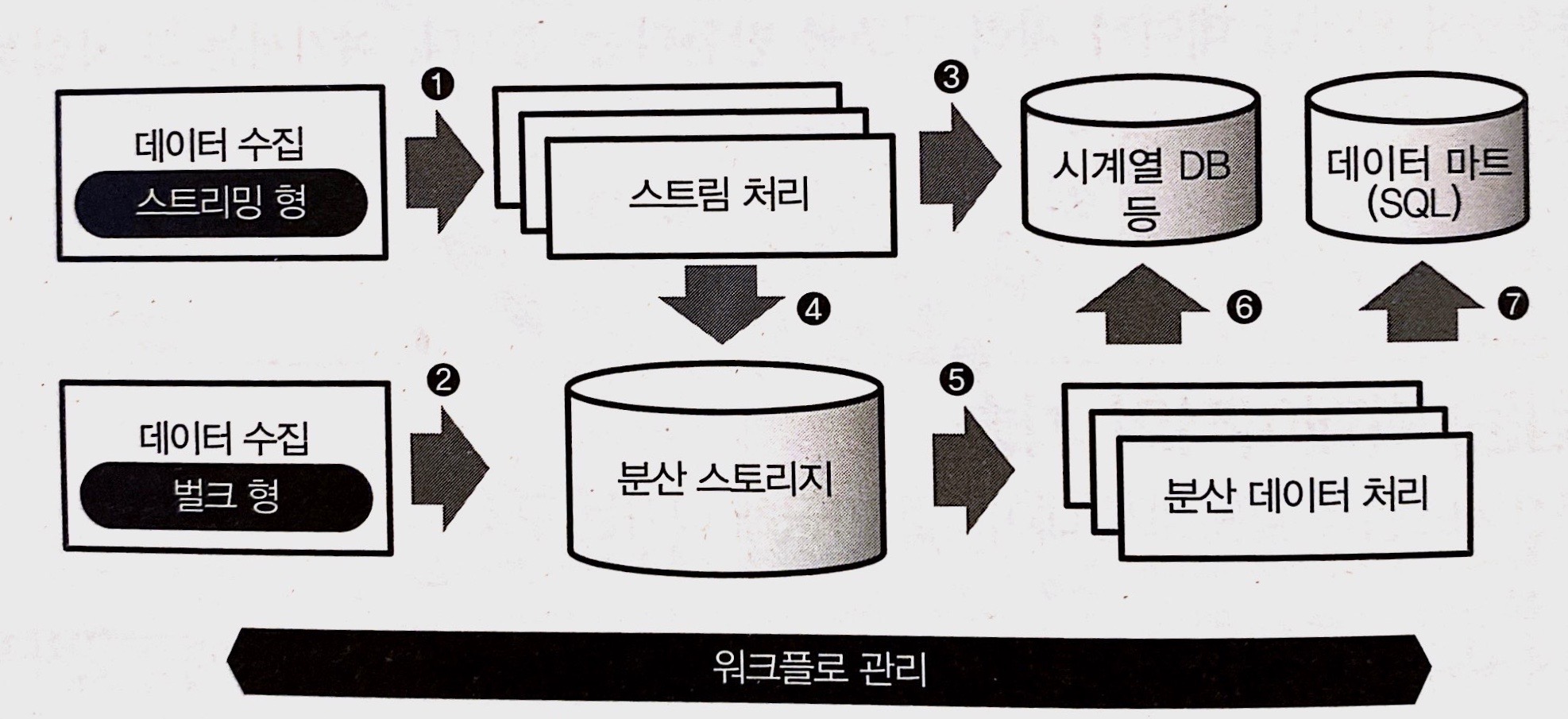
1) 데이터 수집
- 데이터 전송 방법 두 가지
- 벌크 (bulk): 이미 어딘가에 존재하는 데이터를 정리해 추출하는 방법
- 스트리밍 (streaming): 계속 생성되는 데이터를 끊임없이 계속 보내는 방법
- 앱, 임베디드 장비 등에서 데이터를 수집하는데 사용됨
- 최근 주류가 되었음
- 스트림 처리와 배치 처리
- 스트림 처리 (stream processing): 스트리밍 방법으로 받은 데이터를 실시간으로 처리
- 시계열 데이터 베이스: 실시간 처리를 지향한 데이터베이스
- 장기적 데이터 분석에는 적합하지 않음
-
Kafka: Apache의 분산 스트리밍 플랫폼
- 배치 처리 (batch processing): 실시간이 아닌, 어느 정도 정리된 데이터를 효율적으로 가공하기 위한 구조
- 스트림 처리 (stream processing): 스트리밍 방법으로 받은 데이터를 실시간으로 처리
2) 분산 스토리지
- 여러 컴퓨터와 디스크로부터 구성된 스토리지 시스템
-
객체 스토리지 (object storage): 한 덩어리로 모인 데이터에 이름을 부여해 파일로 저장- e.g.) Amazon S3
3) 분산 데이터 처리
- 나중에 분석하기 쉽도록 데이터를 가공해서 그 결과를 외부 데이터베이스에 저장하는 엔진
-
ETL process: Extract-Transform-Load, 분산 스토리지에서 추출한 데이터를 데이터 웨어하우스에 적합한 형식으로 변환 - 쿼리 엔진: Hive와 같이 분산 스토리지 상의 데이터를 SQL로 집계하기 위해 사용하는 엔진
4) 워크플로 관리
- workflow management: 전체 데이터 파이프라인의 동작을 관리하기 위한 것
데이터 레이크 (Data Lake)
모든 데이터를 그대로 저장하고, 나중에 필요한 것만 꺼내서 사용하는 스토리지
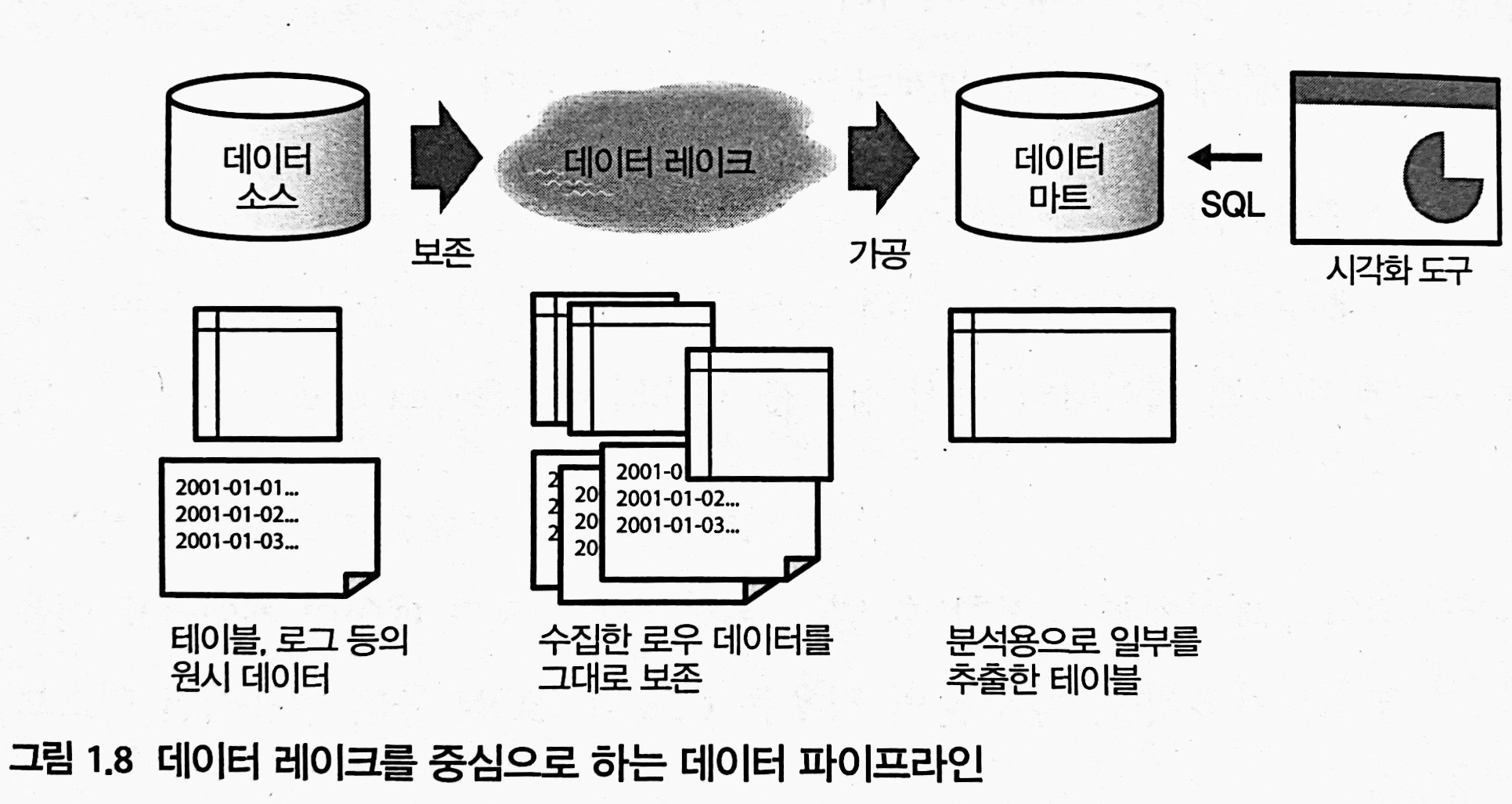
- 빅데이터 시대가 되면서 ETL process가 복잡해졌다. 모든 데이터가 데이터 웨어하우스를 가정해서 만들어지지 않음.
- 따라서, 우선 raw data를 data lake에 축적하고, 나중에 필요에 따라 가공한다. 데이터는 대부분 csv, json type이다.
- 데이터 레이크는 단순한 스토리지기 때문에, MapReduce 같은 분산 데이터 처리 기술이 필요하다.
- Apache Spark: MapReduce보다 더 효율적으로 데이터를 처리