데이터 수집 과정, 메시지 배송, 시계열 데이터
아래 대부분의 내용은 도서 빅데이터를 지탱하는 기술에서 발췌했습니다.
벌크 형 & 스트리밍 형의 데이터 전송, 시계열 데이터 수집을 최적화하는 방법에 대해 알아보자.
객체 스토리지와 데이터 수집
- 객체 스토리지(object storage)
- Hadoop의
HDFS,Amazon S3등 - 다수의 컴퓨터를 사용해 파일을 여러 디스크에 복사해서 데이트의 중복화, 부하 분산을 실현
- 객체 스토리지에서의 파일 I/O는 네트워크를 거쳐서 실행
- 데이터 양이 많을 때에는 우수, 소량의 데이터에 대해서는 비효율적 (통신 오버헤드가 너무 크기 때문)
- Hadoop의
- 데이터 수집
- 수집한 데이터를 가공하여 집계 효율이 좋게 분산 스토리지에 저장하는 프로세스
- 시계열 데이터를 수시로 객체 스토리지에 기록하면 대량의 작은 파일이 생성되어 시간이 지남에 따라 성능을 저하시킴
- 작은 데이터는 적당히 모아 하나의 큰 파일로 만들어 효율을 높이기
- 파일이 지나치게 커져도 네트워크 전송에 시간이 걸려 오류 발생률이 높아짐
- 거대한 데이터는 한번에 처리하지 말고 적당히 나눠 문제 발생을 줄이기
벌크 형의 데이터 전송
- 전통적 데이터 웨어하우스에서 주로 사용되던 방식
- 축적된 대량의 데이터가 이미 있는 경우나 기존의 데이터베이스에서 데이터를 추출하고 싶을 경우
- 데이터 전송을 위한
ETL 서버설치가 필요- ETL 프로세스는 하루마다 또는 1시간 마다의 간격으로 정기적인 실행을 하므로 그동안 축적된 데이터는 하나로 모임
- 한 번에 너무 적지도, 많지도 않은 데이터 양이 전송되도록 조정해야함
- 데이터 전송의 신뢰성이 중요한 경우에는 가능한 벌크 형 도구를 사용하기
- 스트리밍 형의 데이터 전송은 나중에 재실행하기 쉽지 않음
- 벌크 형의 경우, 문제가 발생하면 여러 번 데이터 전송을 재실행할 수 있다
- 벌크 형 데이터 전송은 주로 워크플로 관리 도구와 조합시켜 도입
- 정기적인 스케줄 실행 및 오류 통지 등은 워크플로 관리 도구에 맡김
스트리밍 형의 데이터 전송
- 계속되어 전송되어 오는 작은 데이터를 취급하기 위한 데이터 전송
-
메시지 배송 message delivery- 다수의 클라이언트에서 계속해서 작은 데이터가 전송됨
- 전송되는 데이터 양에 비해 통신을 위한 오버헤드가 커지므로 높은 성능의 서버가 요구됨
- client: 메시지가 처음 생성되는 기기
- front-end: 메시지를 먼저 받는 서버
- 역할: 통신 프로토콜을 제대로 구현하는 것, 메시지 브로커로 메시지를 전송
- 메시지 저장방법
- NoSQL에 데이터를 쓰고 Hive와 같은 쿼리 엔진으로 읽을 수 있음
- 분산 스토리지에 직접 쓰는 것이 아니라, 메시지 큐와 메시지 브로커 등의 중계 시스템에 전송할 수 있음
- 기록된 데이터는 일정한 간격으로 꺼내고 모아 함께 분산 스토리지에 저장
웹 브라우저에서의 메시지 배송
- 웹 서버 안에서 메시지를 만들어 배송
- 전송 효율을 높이기 위해
Fluentd,Logtash와 같은 서버 상주형 로그 수집 소프트웨어를 활용- 내부의 효율적인 버퍼링 메커니즘으로 일정 시간동안 데이터를 축적해두었다가 모아서 보냄
-
웹 이벤트 트래킹 web event tracking- JS를 사용하여 웹 브라우저에서 직접 메시지를 보내는 경우
- HTML 페이지에 태그를 삽입해 각종 액세스 분석, 데이터 분석 서비스 등에서 사용됨
모바일 앱에서의 메시지 배송
- 통신 방법으로 HTTP 프로토콜을 사용하는 클라이언트, 메시지 배송 방식이 웹 브라우저와 동일
-
MBaas(Mobile Backend as a Service)- 서버를 직접 마련하지 않고 백엔드의 각종 데이터 저장 서비스를 이용할 수 있음
-
SDK- 서비스에서 제공되는 모바일 용 편리한 개발 kit
- 모바일 앱에 특화된 액세스 해석 서비스를 통해 이벤트 데이터를 수집
- 모바일 앱은 오프라인이 되는 경우도 많아 발생한 이벤트를 SDK 내부에 일단 축적시키고, 온라인 상태가 되었을 때 모아서 내보냄
디바이스로부터의 메시지 배송
- IoT
-
MQTT- TCP/IP를 사용해 데이터를 전송하는 프로토콜의 하나
- Pub/Sub 형 메시지 배송
- 전달과 구독
- 관리자에 의해
topic이 만들어지고, 이 topic을 구독하는 사람들은 메시지를 받는다. 메시지는MQTT 브로커에 의해 구독자에게 전달된다. - 채팅 시스템, 메시징 앱, 푸시 알림 등의 시스템에서 자주 사용되는 기술
메시지 브로커
- 스토리지의 성능에 관계없이 안정적으로 대량의 메시지를 받도록 하는 중간층
- 분산 스토리지에 직접 메시지를 기록하면 부하 제어가 어려워 성능 한계에 도달하기 쉬움
- 메시지 브로커가 일시적으로 데이터를 축적함으로써 분산 스토리지에 쓰는 속도를 안정화함
-
Apache Kafka,Amazon Kinesis -
메시지 라우팅- 메시지 브로커에 써넣은 데이터를 복수의 다른 소비자가 읽어들이게 해 메시지를 복사, 데이터를 여러 경로로 분기시키는 것
- 메시지 배송의 안정성을 높이는데 유용하지만, 메시지 브로커 자체에 장애가 일어날 수 있으므로 방심하면 안 된다.
메시지 배송의 신뢰성
-
신뢰성 reliability-
모바일 회선과 같은 신뢰성이 낮은 네트워크에서는 반드시 메시지의 중복이나 누락이 발생
-
처리 방법: 다음 중 하나를 보장하도록 설계됨
- at most once
- 메시지는 한 번만 전송됨, 도중에 전송 실패로 결손 발생 가능성이 있음
- 무슨 일이 일어나도 절대로 메시지를 다시 보내지 않음
- 그러나 대개는 재전송이 이루어지므로 at most once를 보장하는 것은 어려움
- exactly once
- 메시지는 손실되거나 중복 없이 한 번만 전달됨
- 메시지 송신/수신 측 모두 서로의 정보를 코디네이터에게 전달함으로써 문제 발생시 코디네이터의 지시에 따라 해결
- 코디네이터가 존재하지 않으면 실현되지 못함
- at least once
- 메시지는 확실히 전달되지만, 중복 가능성이 있음
- 대부분 이를 보장하되, 중복 제거는 사용자에게 맡김
- at most once
-
- 신뢰성이 높은 메시지 배송을 실현하려면, 중간 경로를 모두
at least once로 통일하고, 클라이언트 상에서 모든 메시지에 고유 ID를 포함하도록 하고, 경로의 말단에서 중복 제거를 실행해야 한다.
데이터 수집의 파이프라인
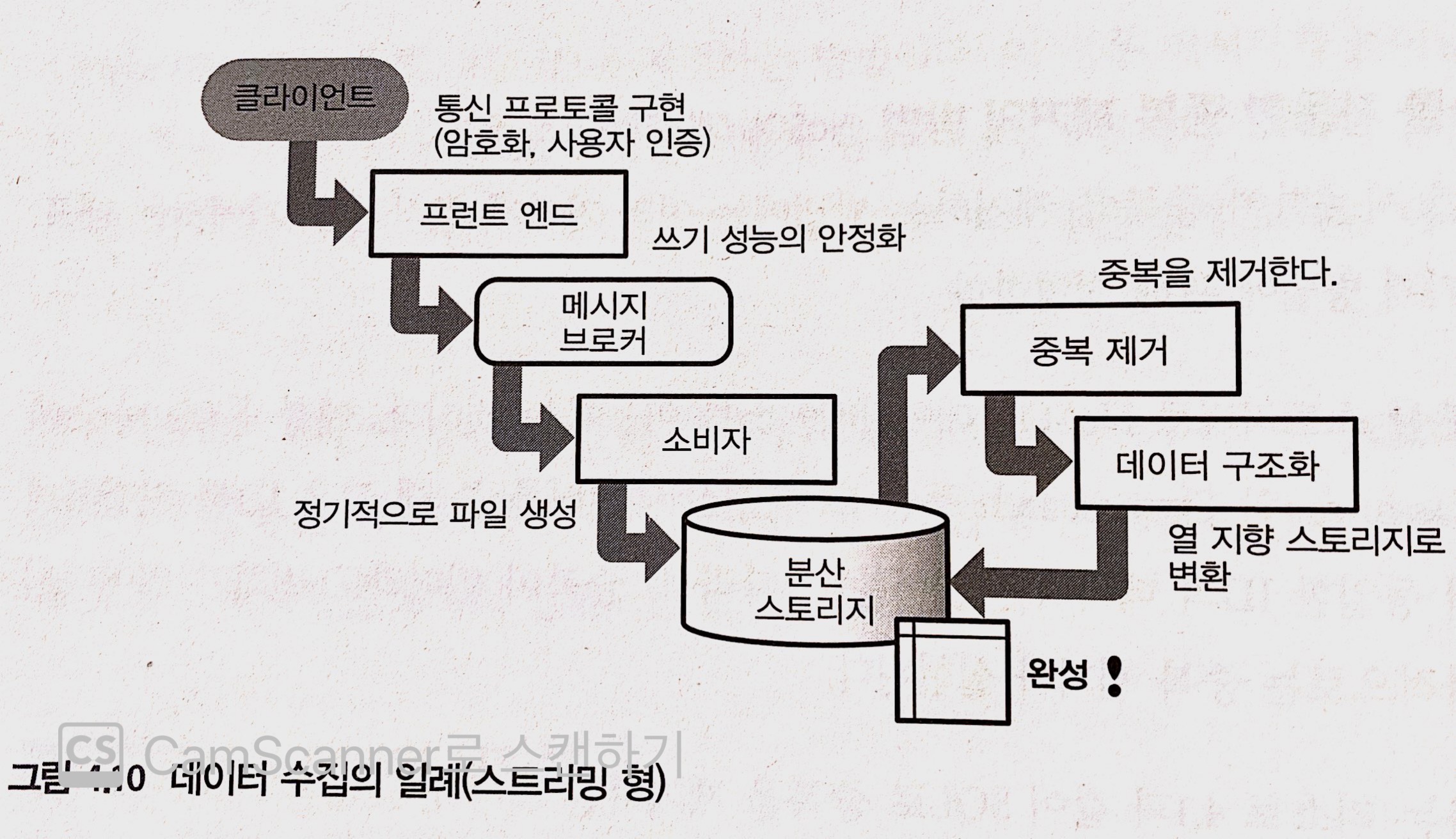
- 요구 사항에 맞게, 필요에 따라 시스템을 조합
시계열 데이터 수집의 문제점
- 스마트폰에서 데이터를 수집하면 오프라인 상태, 방전 등의 이유로 메시지가 지연되는 경우가 흔하다.
-
event time: 클라이언트 상에서 메시지가 생성된 시간 -
process time: 서버가 처리하는 시간 - 며칠 정도의 지연을 예측해 데이터 분석을 고려해야 한다.
- e.g.) 모바일 앱의 활동 사용자 수를 집계할 때 이벤트 시간보다 며칠 정도 지난 시점에서 소급해 집계해야 함
- 분산 스토리지에 데이터를 넣는 단계에서는 프로세스 시간을 사용하는 것이 보통
- 이벤트 시간으로 정렬되지 않기 때문에 모든 데이터를 로드해, 원하는 이벤트 시간을 포함하는지 확인해야 함 - 풀 스캔 발생
-
full scan: 다수의 파일을 모두 검색하는 쿼리, 시스템의 부하를 크게 높이는 요인
시계열 데이터 최적화
- 시계열 인덱스
- 이벤트 시간에 대해 인덱스를 만드는 것
- Cassandra와 같이 시계열 인덱스에 대응하는 분산 데이터베이스를 이용하면 처음부터 이벤트 시간으로 인덱스 된 테이블을 만들 수 있다.
- 하지만, 장기간에 걸쳐 대량의 데이터를 집계하는 경우에는 분산 데이터베이스가 그다지 효율적이지 못함. 열 지향 스토리지를 지속적으로 만들어야 함
- 조건절 푸쉬다운
predicate pushdown- 통계를 이용하여 최소한의 데이터만을 읽도록 하는 최적화
- 열 지향 스토리지를 만들 때 가급적 읽어들이는 데이터의 양을 최소화하도록 데이터를 정렬해둠
- 이 때, 데이터가 연속적으로 배치되어야 최적화 효과가 높아짐
- 데이터 마트를 이벤트 시간으로 정렬하기
- 데이터 마트만이 이벤트 시간에 의한 정렬을 고려하도록 해두는 것
- 데이터 수집 단계에서는 이벤트 시간을 따지지 않고 프로세스 시간만을 사용하여 데이터를 저장