배치형, 스트리밍형의 데이터 플로우
아래 대부분의 내용은 도서 빅데이터를 지탱하는 기술에서 발췌했습니다.
Map and Reduce
-
Map: 분할된 텍스트를 단어별로 수를 카운트 -
Reduce: 단어별 합계를 계산 - Map과 Reduce를 여러번 반복하며 결과를 얻음
데이터 플로우
-
데이터 플로우- 다단계의 데이터 처리를 그대로 분산 시스템 내부에서 실행하는 것
- MapReduce와 같은 외부 도구에 의존하는
워크플로와 구분
- MapReduce를
MillWheel,Tez,Spark등의 프레임워크가 대체하고 있음
DAG
-
DAG- 방향성 비순환 그래프 directed acyclic graph
- 새 프레임워크에 공통으로 들어가는 데이터 구조
- DAG의 성질
- 방향성: 노드와 노드가 화살표로 연결된다.
- 비순환: 화살표를 아무리 따라가도 동일 노드로는 되돌아오지 않는다.
- MapReduce에서는 하나의 노드에서 처리가 끝나지 않으면 다음 처리로 진행할 수 없어 비효율적이었는데, 데이터 플로우에서는 DAG를 구성하는 각 노드가 모두 동시 병행으로 실행된다. 처리가 끝난 데이터는 네트워크를 거쳐 차례대로 전달되어 대기 시간을 없앤다.
- lazy evaluation
- 프로그램의 각 행은 DAG의 데이터 구조를 조립하고 있을 뿐, 뭔가를 처리하지는 않음
- 먼저 데이터 파이프라인 전체를 DAG로 조립하고 나서 실행해 옮김으로써 내부 스케줄러가 분산 시스템에 효과적인 실행 계획을 세워줌
단어를 세는 Spark 프로그램 (배치)
데이터 처리를 하는 파이썬 스크립트의 예시
# 파일로부터 데이터를 읽어들임
lines = sc.textfile("sample.txt")
# 파일의 각 행을 단어로 분해
words = lines.flatMap(lambda line: line.split())
# 단어마다의 카운터를 파일에 출력
words.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b) \
.saveAsTextFile("word_counts") # 여기서 실행 개시
DAG
- textFile()
- flatMap()
- map()
- reduceByKey()
- saveAsTextFile()
데이터 플로우와 워크플로 조합하기
- 태스크의 정기적인 실행, 실패한 태스크를 기록하여 복구하는 것은 데이터 플로우에서 할 수 없으므로 워크플로 관리가 필요함
- 분산 시스템 안에서만 실행되는 데이터 처리라면 하나의 데이터 플로우로 기술할 수 있겠지만, 분산 시스템 외부와 데이터를 주고 받을 경우는 언제 어떤 오류가 생길지 모르므로 복구를 고려해 워크플로 안에서 실행하는 것이 바람직하다.
데이터 읽어 들이는 / 써서 내보내는 플로우
- 데이터 플로우 실행 과정에서 데이터 소스에 직접 액세스하면 성능 문제를 일으키기 쉽다.
- 데이터 플로우로부터 읽어 들일 데이터는 성능적으로 안정된 분산 스토리지에 복사함으로써 안정적으로 사용한다.
- 외부의 데이터 소스에서 데이터를 읽어 들일 때는 어떤 오류가 발생할 지 예측할 수 없으므로 워크플로, 벌크 형의 전송 도구로 태스크를 구현한다.
- 분산 스토리지에 복사한 후로는 데이터 플로우의 전문 분야이다.
- 외부 시스템에 써서 내보내는 경우에는, 분산 스토리지에 취급하기 쉬운 csv와 같은 형태로 변환해 써넣고, 워크플로 안에서 외부 시스템으로 데이터를 전송한다.
배치 처리
스트리밍 형의 데이터 플로우
- 데이터의 실시간 처리를 높이려면, 배치 처리와는 전혀 다른 데이터 파이프라인이 필요
- 배치 처리를 중심으로 하는 데이터 파이프라인은 데이터가 분석할 수 있게 될 때까지 시간이 걸린다.
- 예로, 열 지행 스토리지를 만들기 위해 데이터를 모아 변환하는 데 일정 시간이 필요하다.
- 이벤트 발생에서 몇 초 후에는 결과를 알 수 있는 실시간의 데이터 처리에서는 그런 과정을 생략한 별개의 계통으로 파이프라인을 만든다.
-
스트림 처리- 분산 스토리지를 거치지 않고 처리를 계속하는 것
- 데이터 양이 너무 많아 분산 스토리지의 비용상, 성능상 한계를 넘어선다면 스트림 처리를 사용해 현실적인 흐름량을 줄일 수도 있음
- 1초마다 통계량만 저장하고 싶으면 집계를 스트림 처리에 맡길 수도 있음
실시간 성이 높은 데이터 처리 시스템의 예
- 시스템 모니터링
- 서버와 네트워크의 상태를 감시하고 그 시간 추이를 그래프로 표시
- 로그 관리 시스템
- 운영체제의 시스템 이벤트나 로그 파일을 검색해 비정상적인 상태라면 경고를 생성
- 복합 이벤트 처리
- 다수의 업무 시스템으로부터 보내온 이벤트를 자동으로 처리
스트림 처리와 배치 처리의 차이
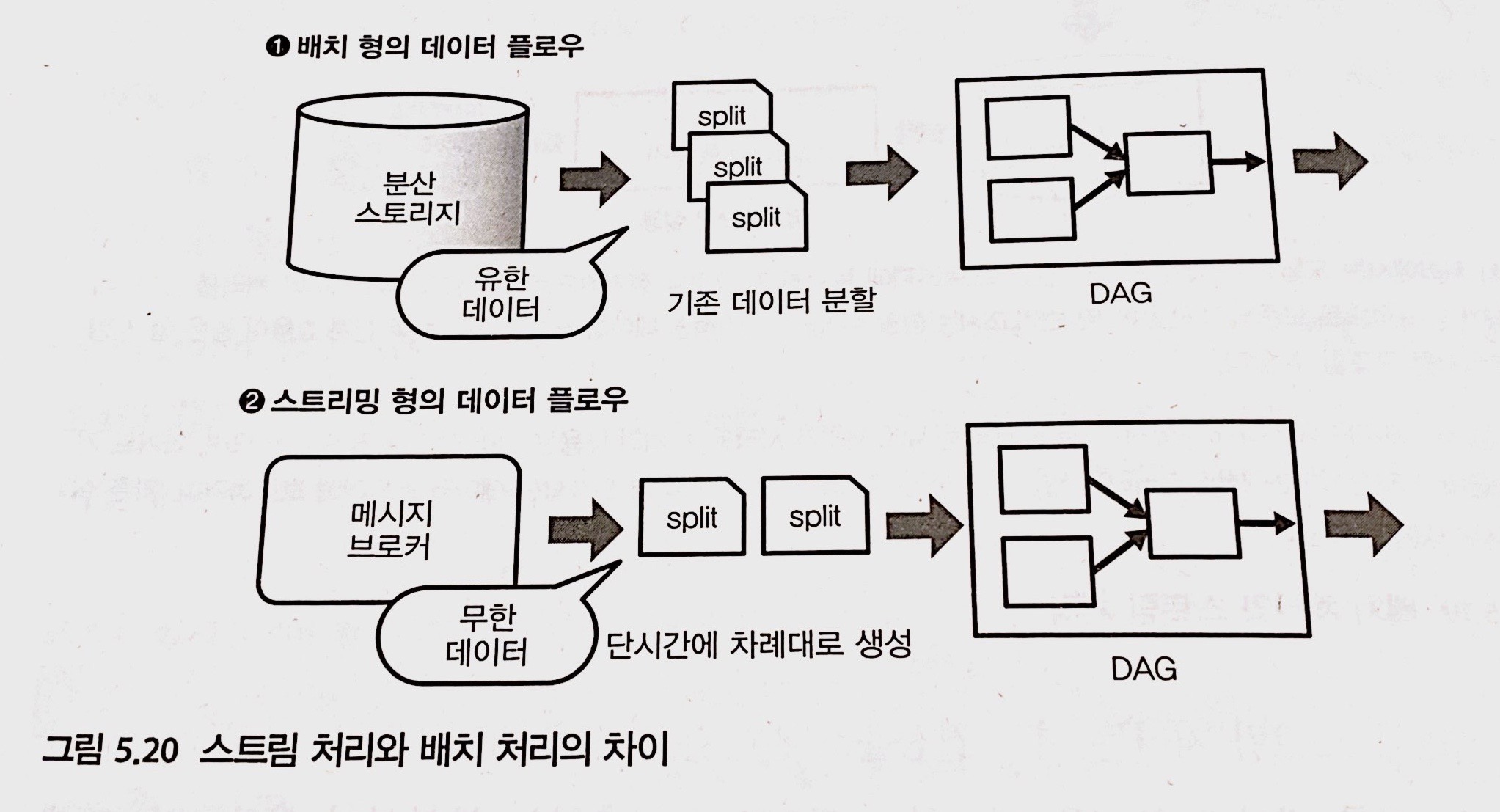
- 데이터를 작게 분할해 DAG에서 실행한다는 점에서는 같음
- 데이터의 처리가 끝나면 배치 처리는 종료, 반면 스트림 처리는 프로그램을 정지할 때까지 끝없이 실행이 계속됨
- 하나의 프레임 워크에서 통합적인 데이터 처리를 기술할 수 있다는 점이 데이터 플로우의 장점
단어를 세는 Spark 프로그램 (스트림)
# 1초마다 스트림 처리를 한다.
sc = SparkContext("local[2]", "NetworkWordCount")
ssc = StreamingContext(sc, 1)
# TCP 포트 9999로부터 데이터를 읽어들인다.
lines = ssc.socketTextStream("localhost", 9999)
# 파일의 각 행을 단어로 분해
words = lines.flatMap(lambda line: line.split())
# 단어별 개수를 콘솔에 출력
words.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b) \
.pprint()
# 스트림 처리를 시작한다.
ssc.start()
람다 아키텍처
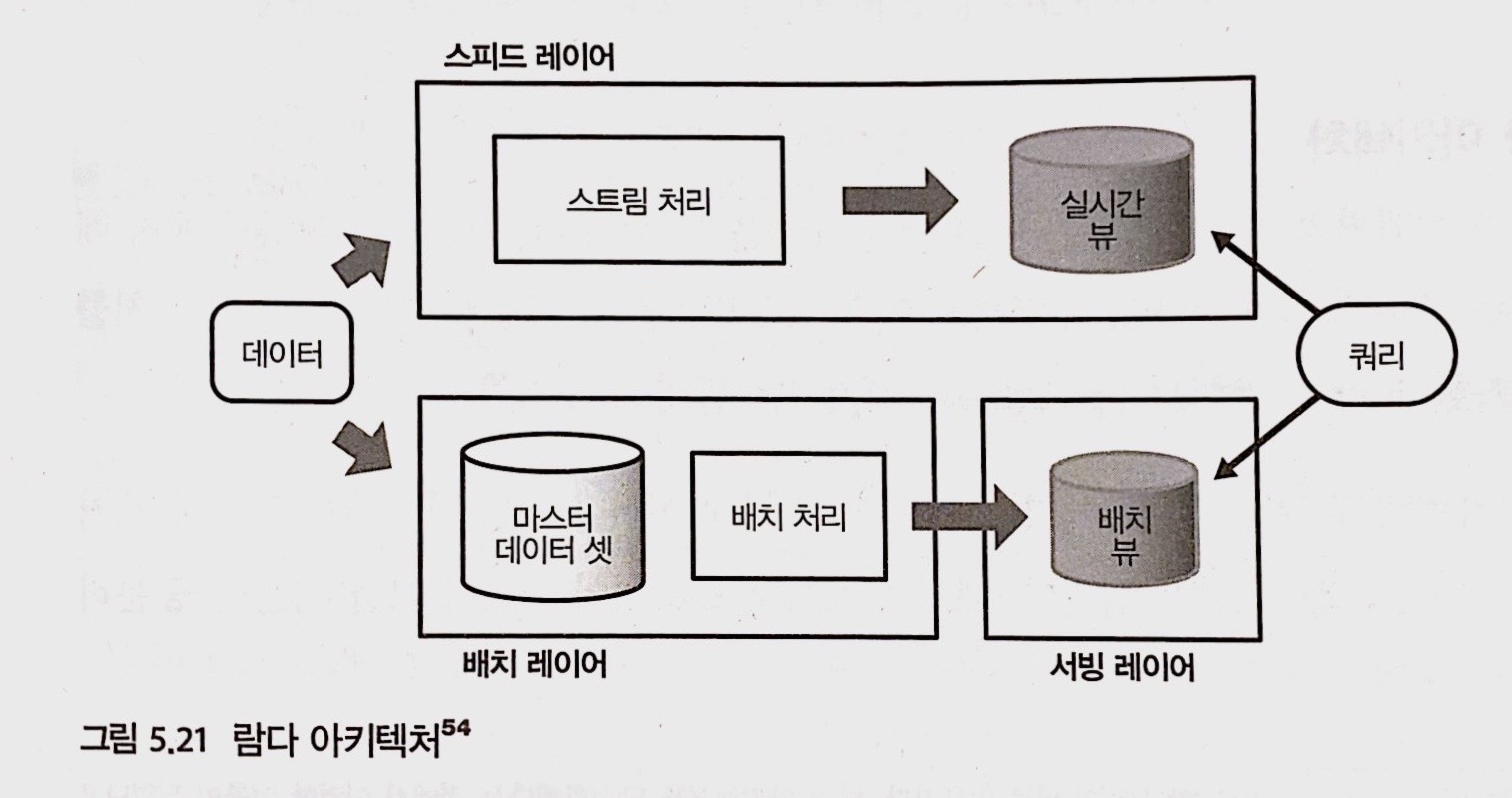
- 스트림 처리는 잘못된 집계를 다시 하는 것이 어렵고, 늦게 전송된 데이터 취급이 어려우므로 배치 처리와 조합시켜 2계통의 데이터 처리를 하게 된다.
- e.g.) 일별 보고서는 속보 값으로, 월별 보고서를 확정 값으로 분류
- 람다 아키텍처의 도입은 시스템을 복잡하게 하는 요인이 되므로, 꼭 필요하지 않은 경우 스트림 처리의 도입에는 신중해야 한다.
- 데이터 파이프라인을 3개의 레이어로 구분
- 모든 데이터는 반드시 배치 레이어에서 처리
- 데이터 처리 결과는 서빙 레이어를 통해 접근
- 배치 뷰: 서빙 레이어에서 얻어진 결과, 정기적으로 업데이트 되고 실시간 정보는 얻을 수 없음
- 스피드 레이어
- 실시간 뷰: 스피드 레이어에서 얻은 결과
- 실시간 뷰는 배치 뷰가 업데이트될 동안까지만 이용되고 오래된 데이터는 순서대로 삭제됨
- 배치 뷰와 실시간 뷰 모두를 조합시키는 형태로 쿼리를 실행
- 문제점: 나쁜 개발 효율
- 스피드 레이어, 배치 레이어는 모두 똑같은 처리를 구현하고 있어 번거로움
카파 아키텍처
- 람다 아키첵처를 단순화함
- 배치 레이어, 서빙 레이어를 제거하고 스피드 레이어만 남기는 대신 메시지 브로커의 데이터 보관 기간을 충분히 길게 하여 문제가 발생했을 때 메시지 배송 시간을 다시 과거로 설정한다.
- 문제점: 부하가 높음
- 스트림 처리의 데이터 플로우에 대량의 과거 데이터를 흘려 보매념 계산 자원을 일시적으로 과다하게 소비함
- 클라우드 서비스 보급으로 이러한 자원 확보가 어렵지 않게 되어서 필요에 따라서는 스트림 처리를 다시 하는 것이 간단하다는 것이 카파 아키텍처의 생각
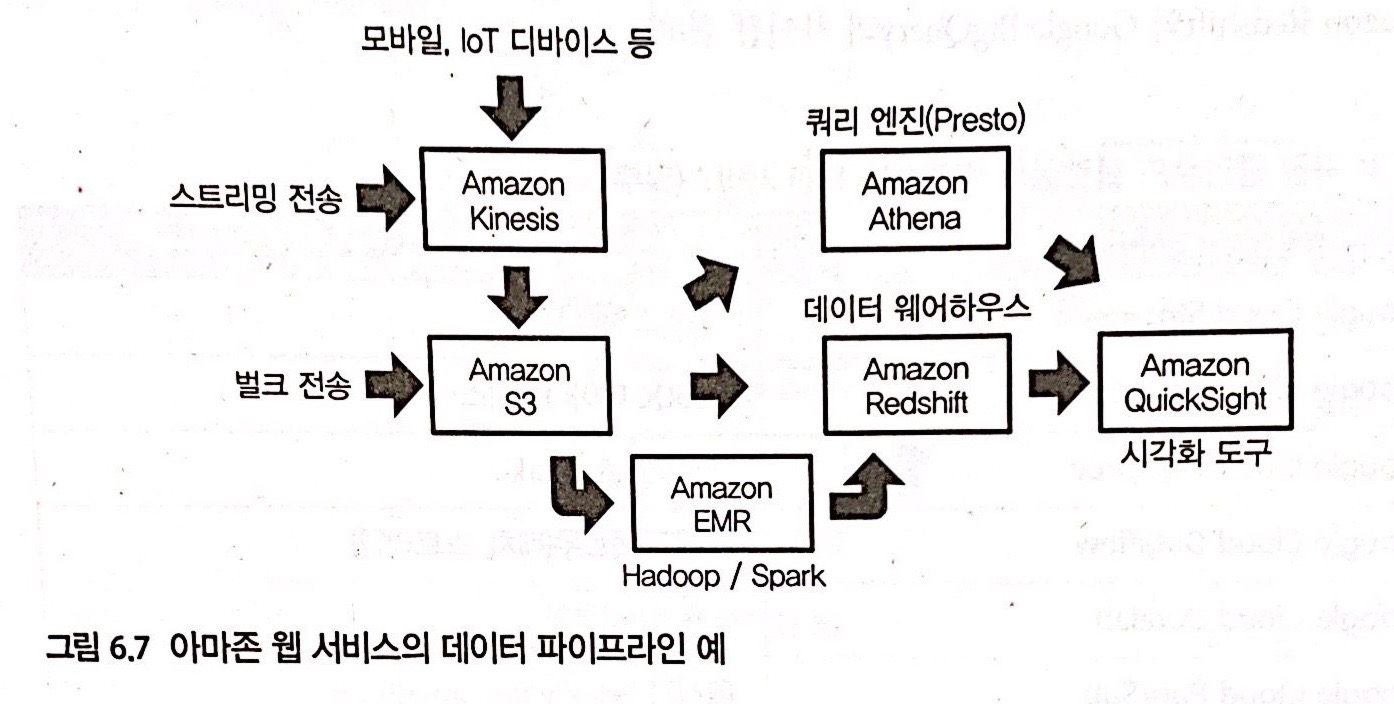
빅데이터 분석 기반의 예
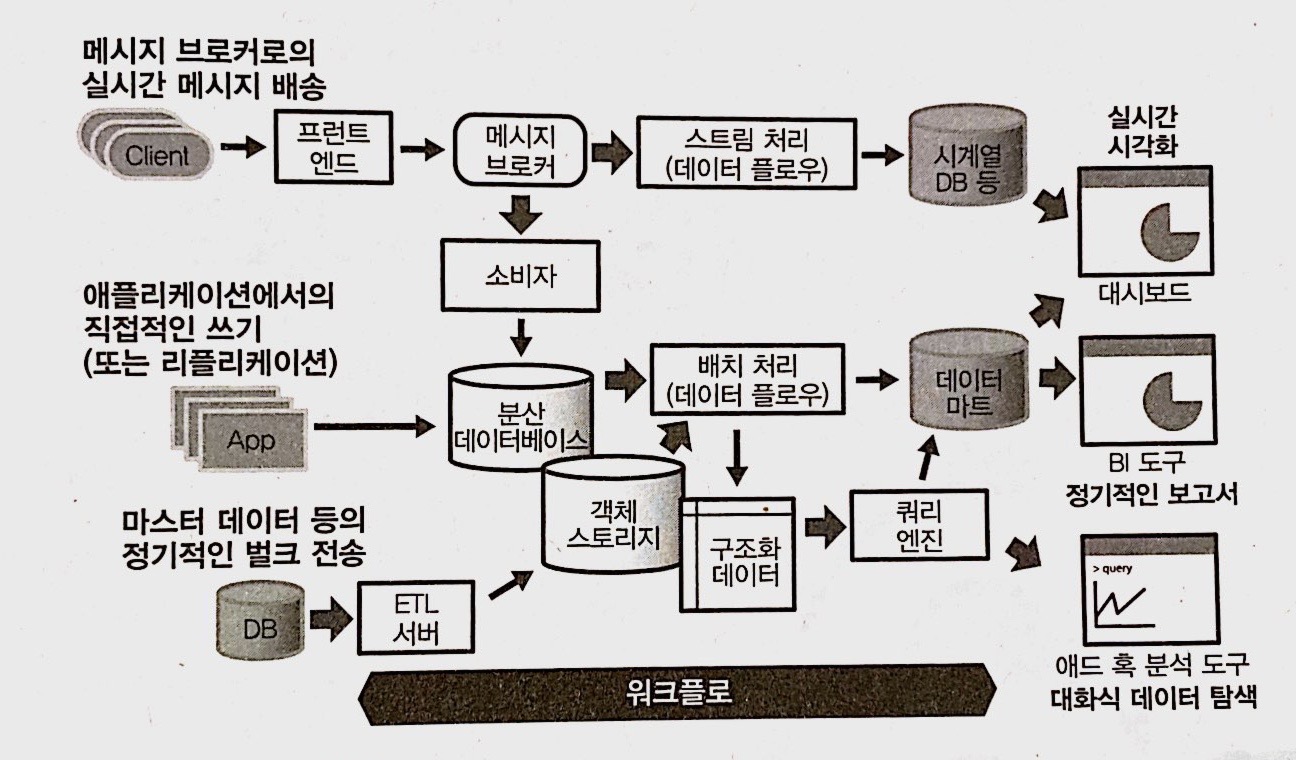
AWS 데이터 파이프라인 예시
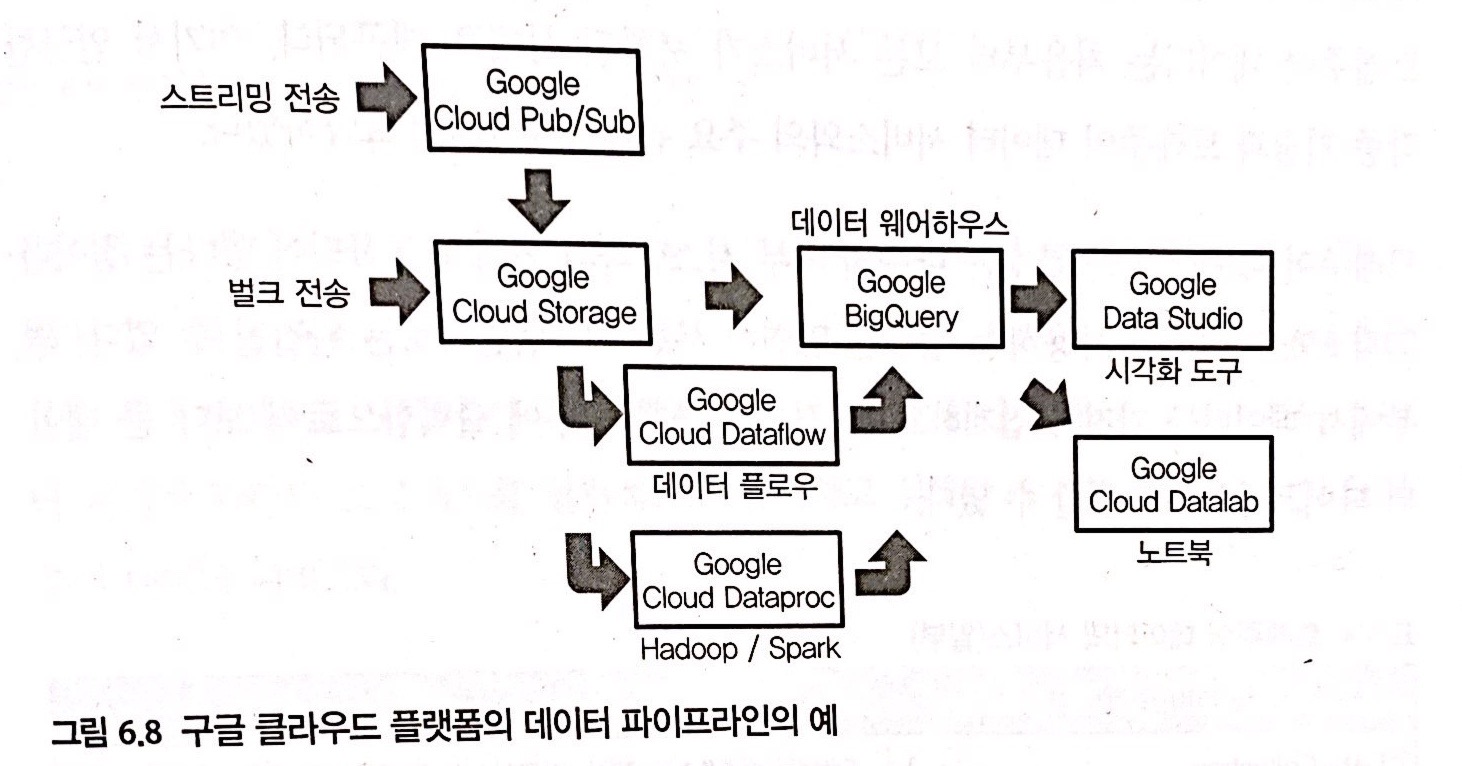
GCP 데이터 파이프라인 예시