Convolutional Neural Networks
Sung Kim 교수님 강의로 공부하는 머신러닝 Section 11
Convolutional Neural Network의 Conv 레이어 만들기
CNN의 Idea 고양이가 어떤 이미지를 볼 때, 이미지를 여러 부분으로 나누어 보고, 각각의 부분들을 보는데 다른 뉴런이 활성화된다는 것을 발견했다. 이에 착안하여 입력을 나누어 x 받는 신경망을 구축한 것이 CNN이다.

하나의 사진을 여러 개의 layer로 자른다. 이 하나의 layer를 Convolutional Layer라고 부른다. 그리고 ReLU 함수를 중간에 넣는다. 그리고, Pooling이라는 것을 중간에 한 번씩 하고, 이 과정을 반복한다. 마지막에는 FC (Fully Conncted Neural Network)를 구성해서 모델을 완성한다.
그러면 단계적으로 알아보자.
1. Start with an image (width x height x depth)
예로, 이미지 사이즈가 32x32x3인 이미지가 있다고 하자.
2. Let’s focus on a small area only
그러면 먼저, 이미지의 일부분만 처리한다. 5x5x3으로 필터 사이즈를 정한다.
3. Get one number using the filter
이 필터는 한 값을 만들어낸다. 어떻게 한 값을 만들어 낼까? 우리가 hypothesis로 사용했던 $Wx+b$ 식을 이용한다. 만약, ReLU를 붙이고 싶다면 ReLU$(Wx+b)$ 식을 사용한다.
4. Let’s look at other areas with the same filter (w)
필터 (w)의 값은 변하지 않는다. 이 똑같은 값을 가지고 다른 부분의 이미지를 봐야 한다. 옆으로 넘기면서 각 부분의 값들을 구한다. 같은 필터로 전체 이미지를 한 번 훑는 것이다.
우리는 output으로 몇개의 수를 얻을 수 있을까? 수월한 계산을 위해 더 작은 사이즈를 살펴보자.
7x7 input이 있을 때, 3x3 필터를 사용한다고 가정하자. 만약 한 칸씩 움직이면, 가로로 5번, 세로로 5번 갈 수 있기 때문에 5x5 output을 얻을 수 있다. 이때의 칸을 stride라고 한다. 이 경우에서는 stride가 1인 것이다.
만약 stride를 2로 하면, 3x3 output을 얻을 수 있다. 이를 일반화하면, output size는 다음과 같이 구할 수 있다.
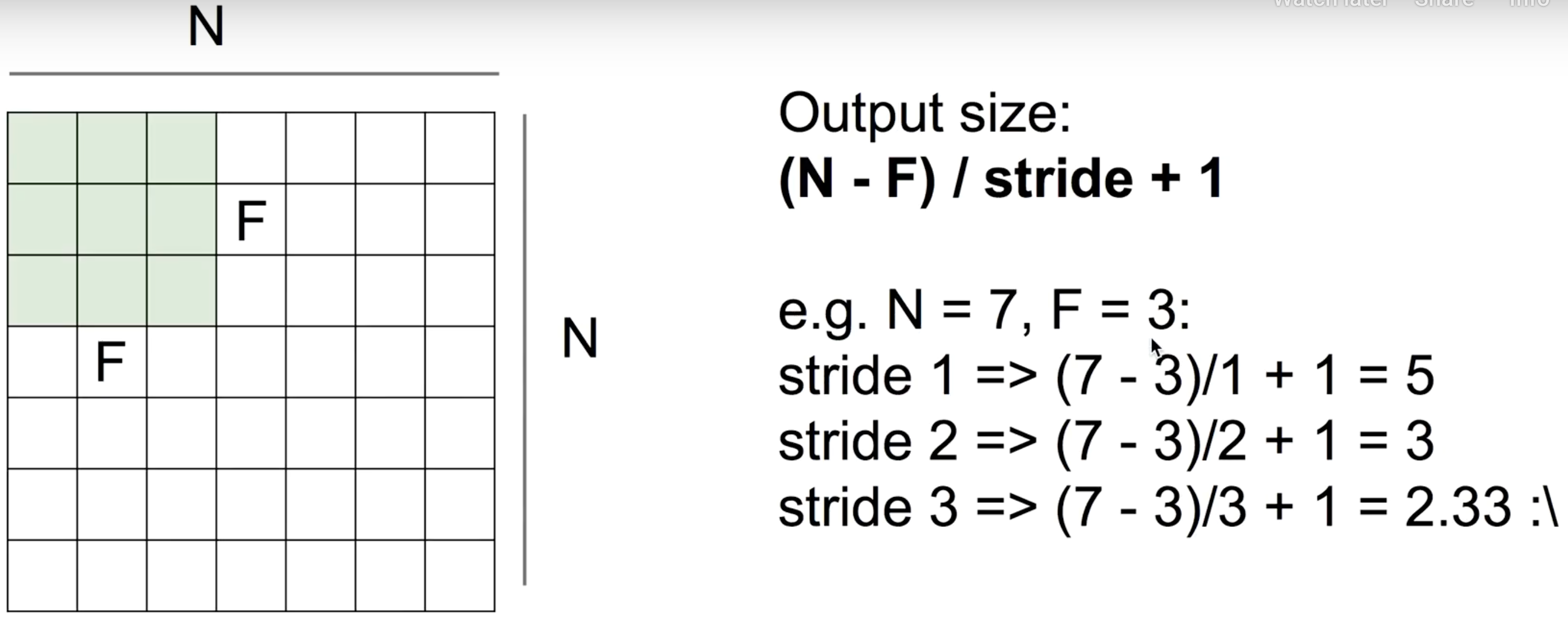
이 stride를 계속 크게 잡다보면, 문제가 output 이미지가 계속 작아진다는 것이다. 이렇게 작아질 수록 우리는 정보를 잃어버리게 된다. 그래서 보통 CNN을 사용할 때는, Padding이라는 개념을 사용한다.
Padding Common to zero pad the border
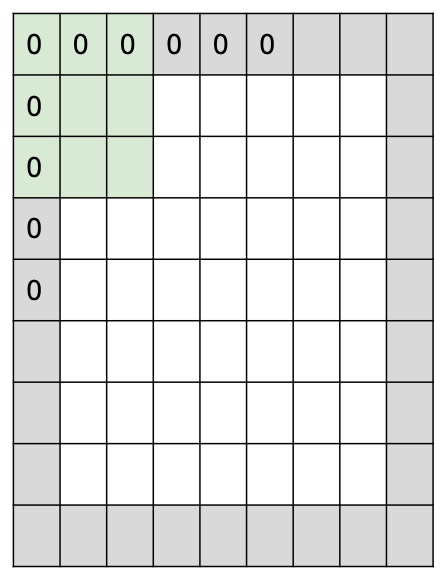
가상으로 0으로 테두리를 두른 입력을 만들어주는 것이다. 이는 첫째, 그림이 급격하게 작아지는 것을 방지하고, 둘쩨, 모서리를 알려주는 역할을 한다.
7x7 이미지에 1 pixel로 패딩을 하게 되면, 이미지 사이즈가 9x9로 변하게 된다. 그러면 stride를 1로 둔다고 하면, output size는 7x7이 나온다.
이렇게 padding을 사용해 입력값과 출력값의 size를 같게 해주는 방법이 보통 사용되고 있다.
5. Swiping the entire images
다른 set의 weight을 적용해 여러 개의 filter를 만든다. 그리고 이 만들어진 여러 개의 filer를 Convolutional Layer에 적용시킨다.
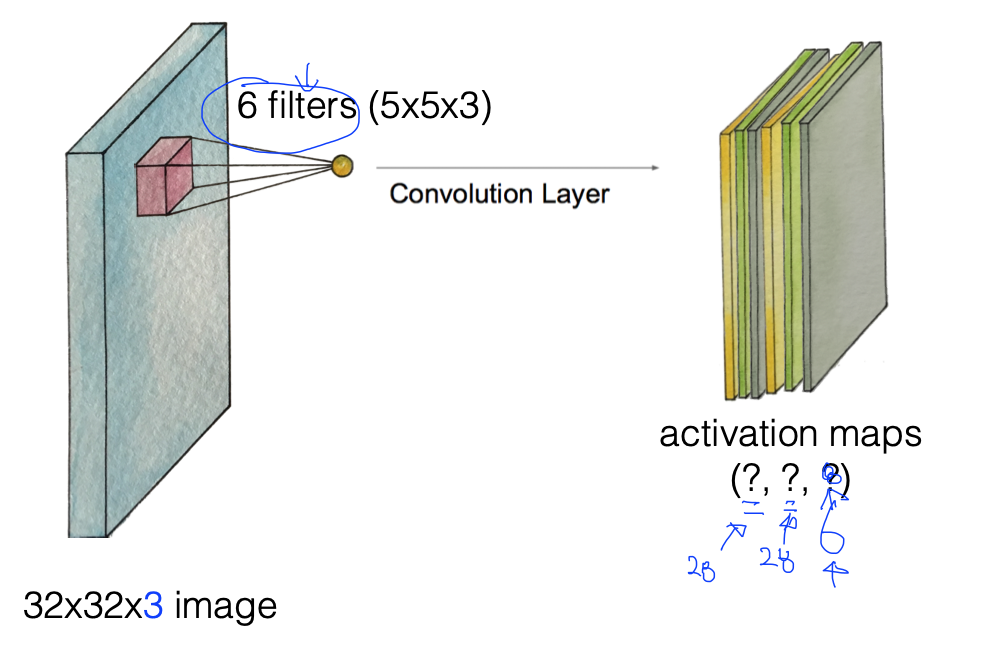
만약 위와 같이 32x32x3의 이미지를 5x5x3의 필터 6개로 layer를 만들게 되면, (28, 28, 6)의 activation maps를 얻을 수 있다.
6. 반복: Convolution layers
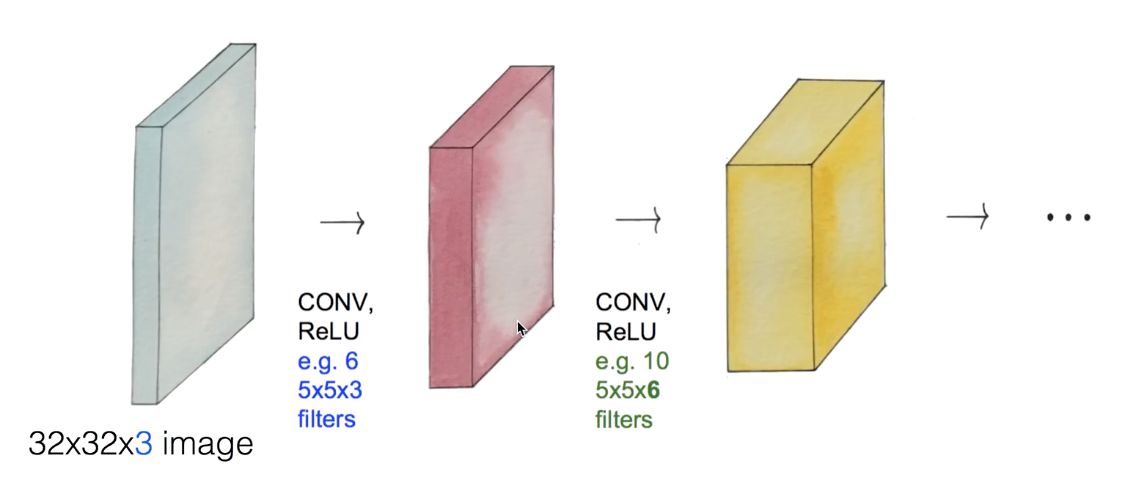
이렇게 Convolutional Layer가 반복되게 구성할 수 있다.
여기서 짚고 넘어가야할 점은, weight variable의 개수와, 이를 어떻게 설정하는 지이다. weight의 개수는 필터의 개수로 알 수 있다. 그리고 weight 값은 처음에 초기화를 하고, 우리가 가진 데이터로 학습을 해서 구하면 된다.
CNN Max Pooling
Pooling layer는 결국 sampling하는 것이다. 이미지를 resize해서 크기를 줄이는 것을 pooling이라고 한다.
Pooling에서는 Max Pooling이 가장 많이 사용된다고 한다.
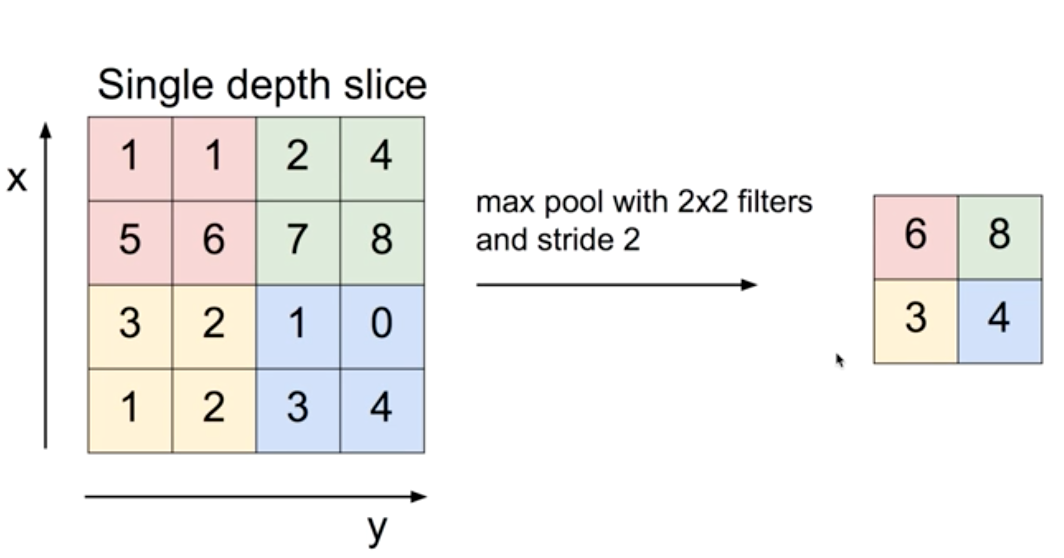
Max Pooling은 각 부분에서 가장 큰 값을 적는 것이다. 위의 그림에서는 2x2 필터, stride 2로 4x4 사이즈를 2x2로 pooling했다. 각 부분에서 가장 큰 값을 적었다.
다시 이 그림을 살펴보면, Convolutional Layer를 쌓고, ReLU를 적용시키고, 다시 이를 반복, 중간에 Pooling을 진행한다. 이 순서는 자기 마음대로 할 수 있다.
마지막에 나온 레이어를 일반적인 Fully Connected Network에 입력으로 넣으면 된다. Network의 깊이는 알아서 정한다. 이 네트워크의 마지막에 나온 값으로 label을 정하면 된다.
CNN Case Study
CNN을 어떻게 활용한 예를 알아보자. 강의 초반에 LeNet-5, AlexNet, GoogLeNet을 소개하셨는데, 이는 생략하기로 하겠다.
ResNet은 ILSVRC, ImageNet Competition의 2015 winner이다. 특이한 점은 152개의 layer를 사용했는 것이다. 타 방법과 비교해보면, AlexNet은 8개의 레이어를 사용했다.
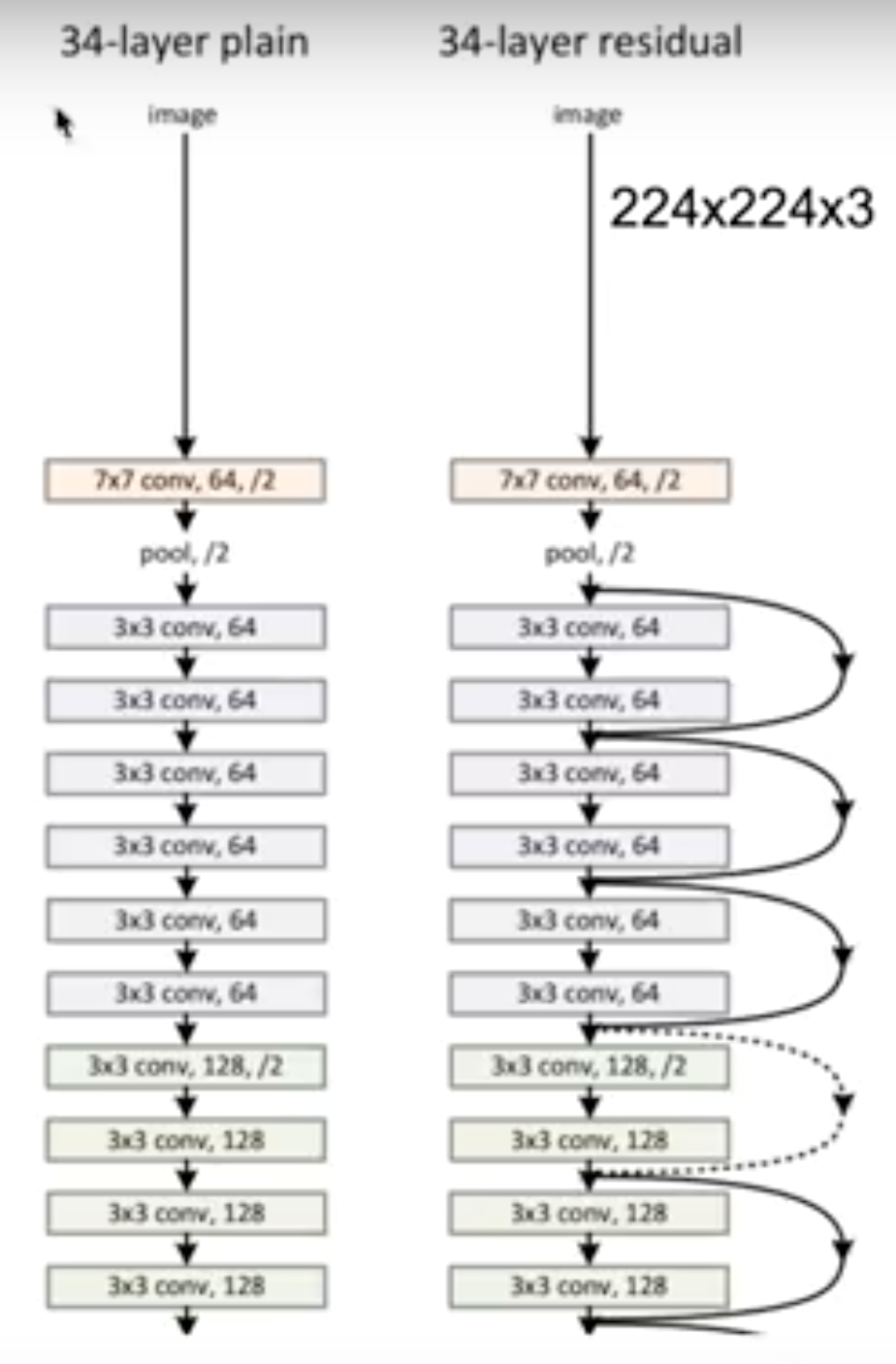
레이어가 많으면 학습하기 어렵다는 단점이 있는데, 이를 극복하기 위해 Fast Forward 개념을 사용했다. 이 때문에, layer가 깊어도 깊지 않은 느낌으로 학습할 수 있게 된다.
이 CNN을 텍스트에도 활용해, Yoon Kim 박사는 Sentence Classification에 이를 활용했다.
그리고 알파고도 CNN을 사용했다.