Recurrent Neural Network
Sung Kim 교수님 강의로 공부하는 머신러닝 Section 12
RNN
교수님은 강의에서 RNN을 가장 재밌는 Neural Network이고, NN의 꽃이라고 소개하셨다.
Sequence Data
- We don’t understand one word only
- We understand based on the previous words + this word. (time series)
- NN/CNN cannot do this
이런 Sequence Data를 이해하기 위해 고안해낸 것이 다음과 같은 구조의 RNN이다.
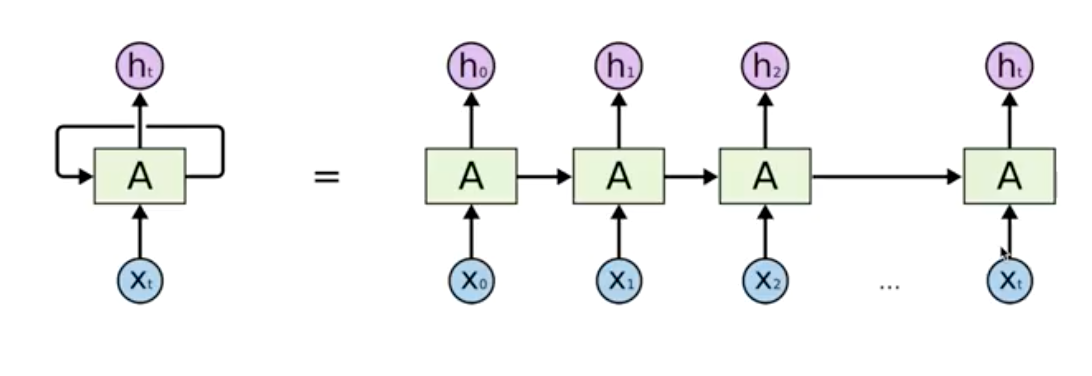
요약하면 왼쪽의 구조처럼 생겼고, 실제로는 오른쪽과 같이 작동한다. 특정 시점에서 이전의 state, 연산들이 영향을 미치게 되고, series를 구성한다.
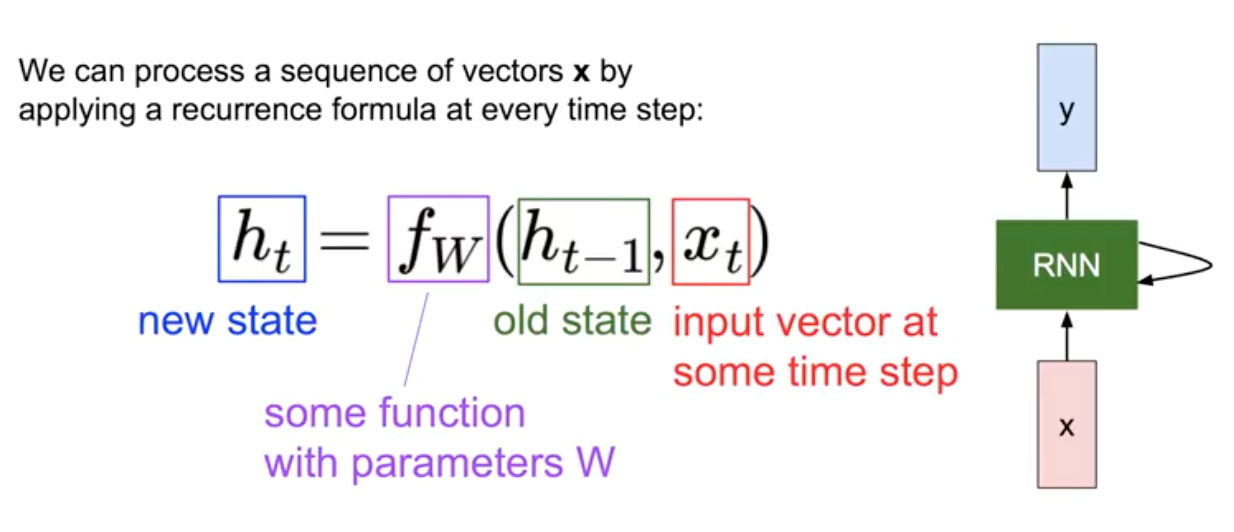
새로운 state $h_t$를 계산할 때, 이전의 state인 $h_{t-1}$와, input vector $x$가 사용된다. 이 때, 모든 연산에서 function $f_W$는 같다.
Vanila RNN
가장 기초가 되는 Vanila RNN의 연산 방법은 다음과 같다.
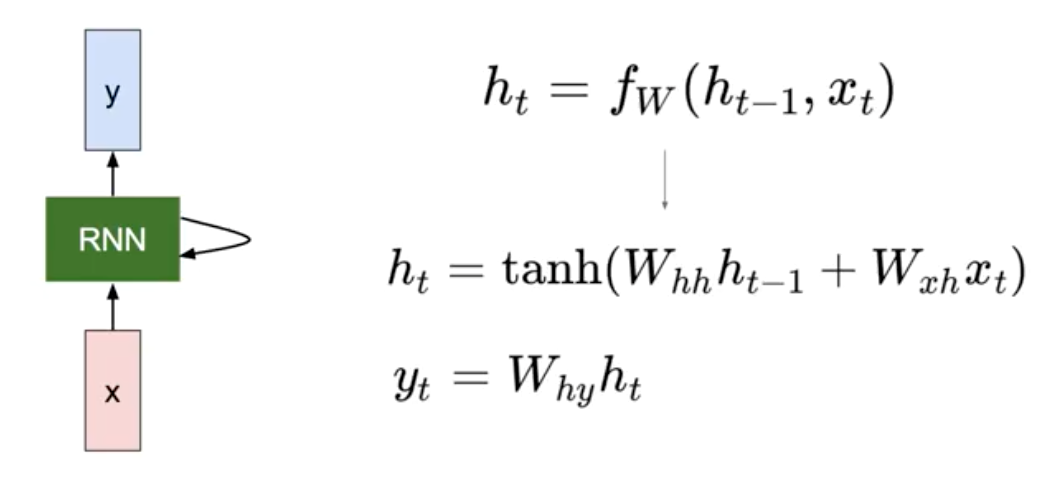
보다시피, h, x, y는 각각의 weight를 가진다. 이 weight는 모든 연산에서 동일하게 적용됨을 주의하자.
Character-level language model example
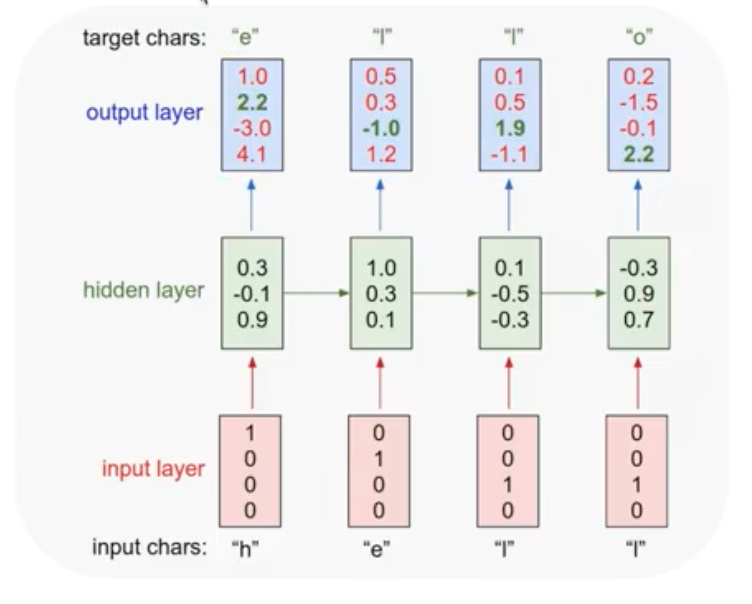
Training sequence가 "hello"라고 하자. 그러면 모델은 h가 들어왔을 때, 다음 단어인 e를 예측해야 한다. 마지막 l이 들어왔을 때는, o를 예측해야 한다.
차근차근 살펴보자. 그림에서 아래쪽부터 위쪽으로 진행되는 모델이다.
가장 아래를 보면 input character들이 있다. 이 문자들을 우선 one-hot encoding을 이용해 벡터로 만들어준다. 해당하는 문자를 1로 표시하는 벡터를 만들어 input layer를 만들어준다.
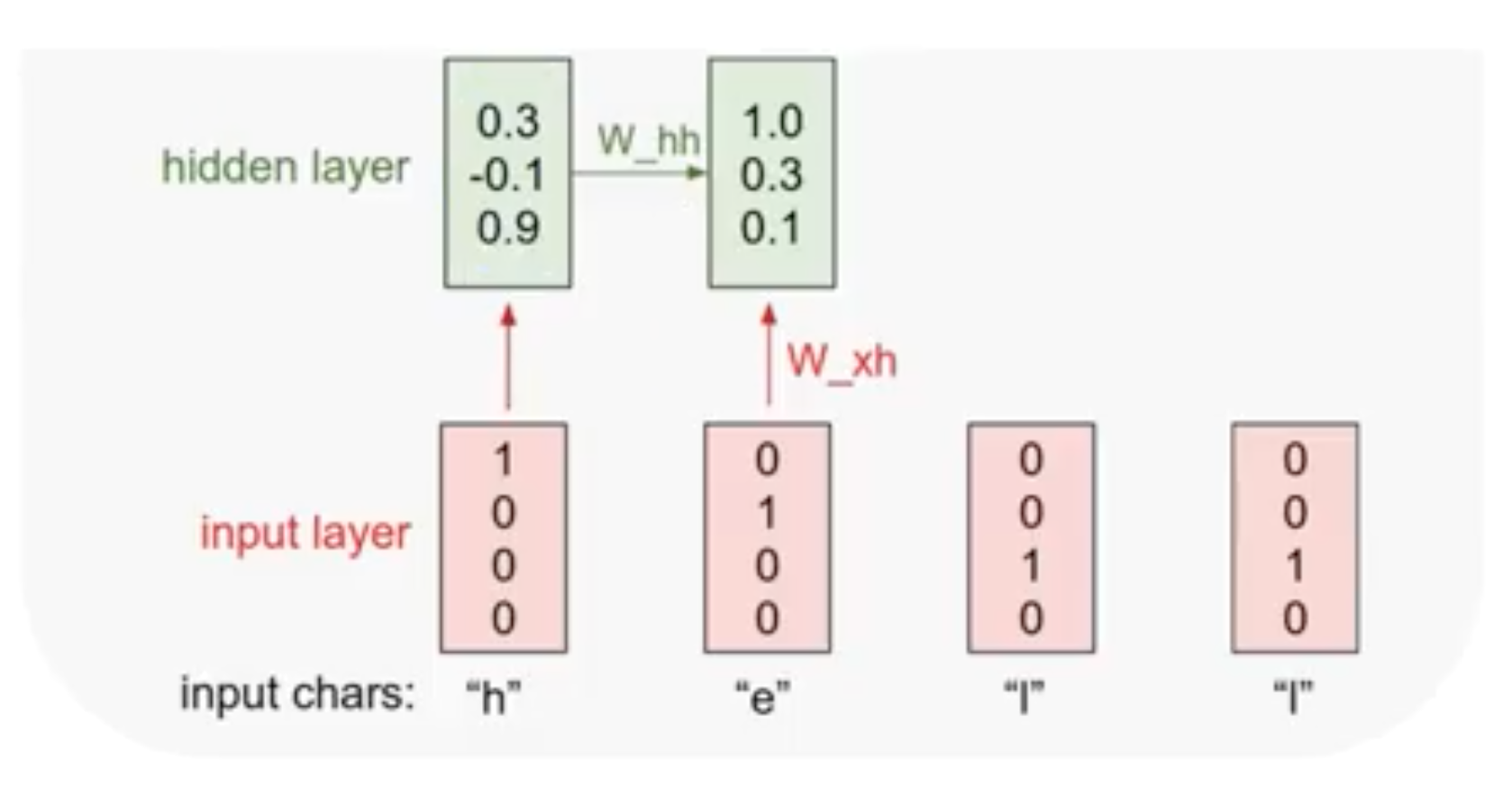
그 다음 단계로 위의 $h_t$ 공식을 이용해 hidden layer를 구성한다. 이때 가장 첫 순서에서는 이전의 state인 $h_{t-1}$가 존재하지 않으므로, 보통 값을 0으로 두고 계산한다. 이전의 state를 적용하며 계산을 반복해 각각의 hidden layer를 만든다.
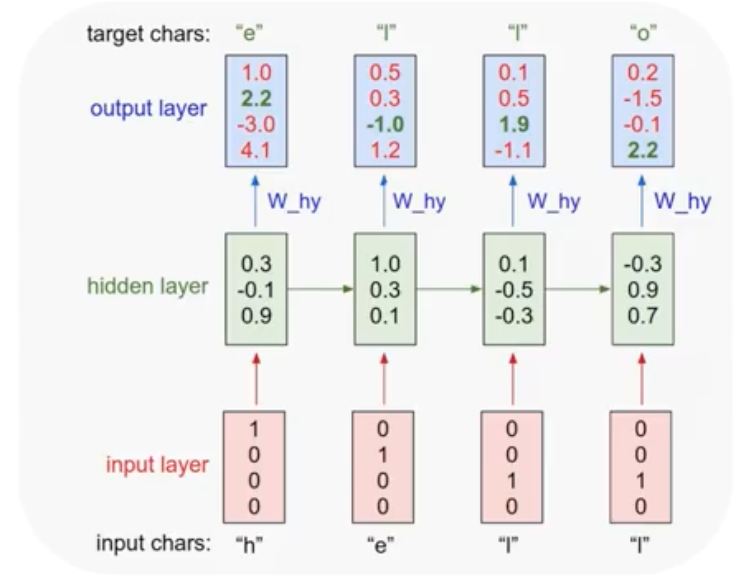
여기에 $W_hy$를 적용해 output layer를 구성한다. Softmax를 적용해, target character를 구할 수 있다. 보다시피 “e”에서 “l”을 구하는 부분에서 error가 났음을 알 수 있다. 나머지는 정상적으로 작동한다.
실제 나온 값들과 비교해 Softmax로 Cost 함수를 구해 학습을 시키면 된다. 여기서는 네 개를 더하는 형태가 될 것이다.
RNN applications
- Language Modeling
- 좀 전에 구현한 모델과 같은 활용이다.
- Speech Recognition
- Machine Translation
- Conversation Modeling/Question
- 챗봇을 만들어 낼 수 있다. “안녕”이란 말이 들어왔을 때, “나도”라는 문자열을 만들어내는 모델링를 할 수 있다.
- Answering Image/Video Captioning
- Image/Music/Dance Generation
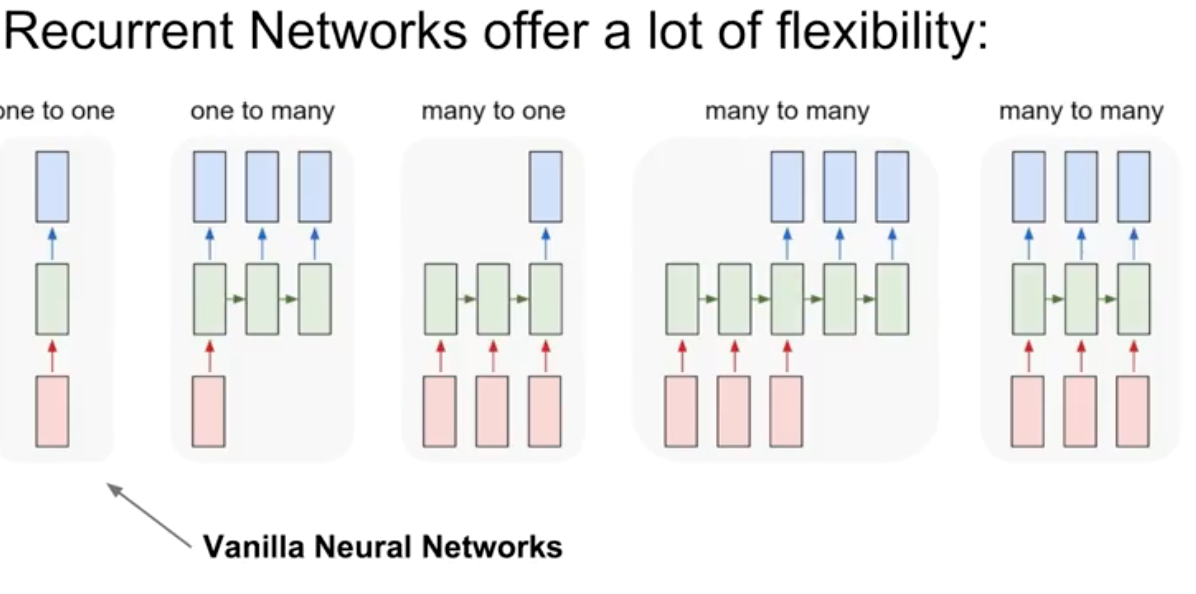
이와 같이 RNN을 다양한 형태로 구현해, 위와 같은 모델링을 해볼 수 있다.
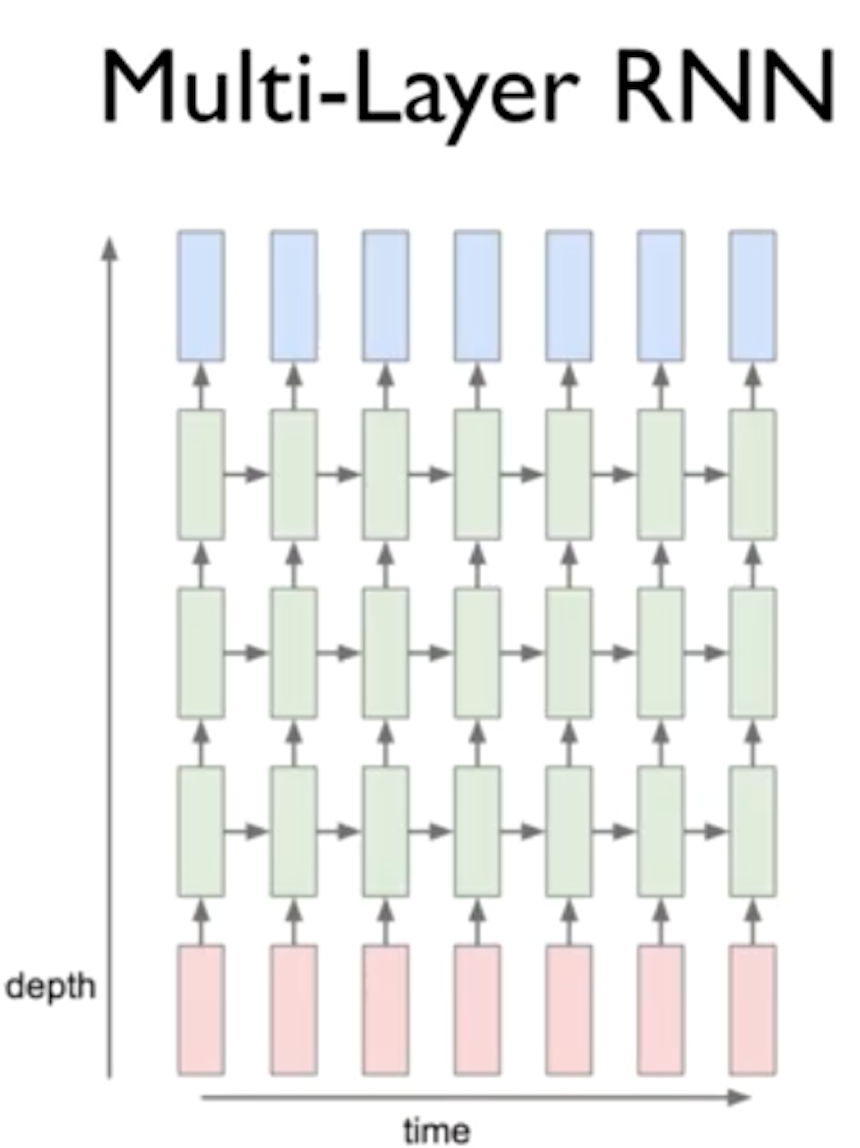
RNN 역시 여러개의 layer를 두어 복잡한 학습을 가능하게 할 수 있다.
RNN을 학습하는 것에는 어려움이 있다. 따라서 Long Short Term Memory (LSTM), GRU 같은 advanced model들이 존재한다.