Machine Learning Application & Tips
Sung Kim 교수님 강의로 공부하는 머신러닝 Section 7
Learning rate
learning rate는 임의의 값이다. 그러면 이 learning rate는 어떻게 정할까?
만약, learning rate가 너무 크면 overshooting하게 된다.
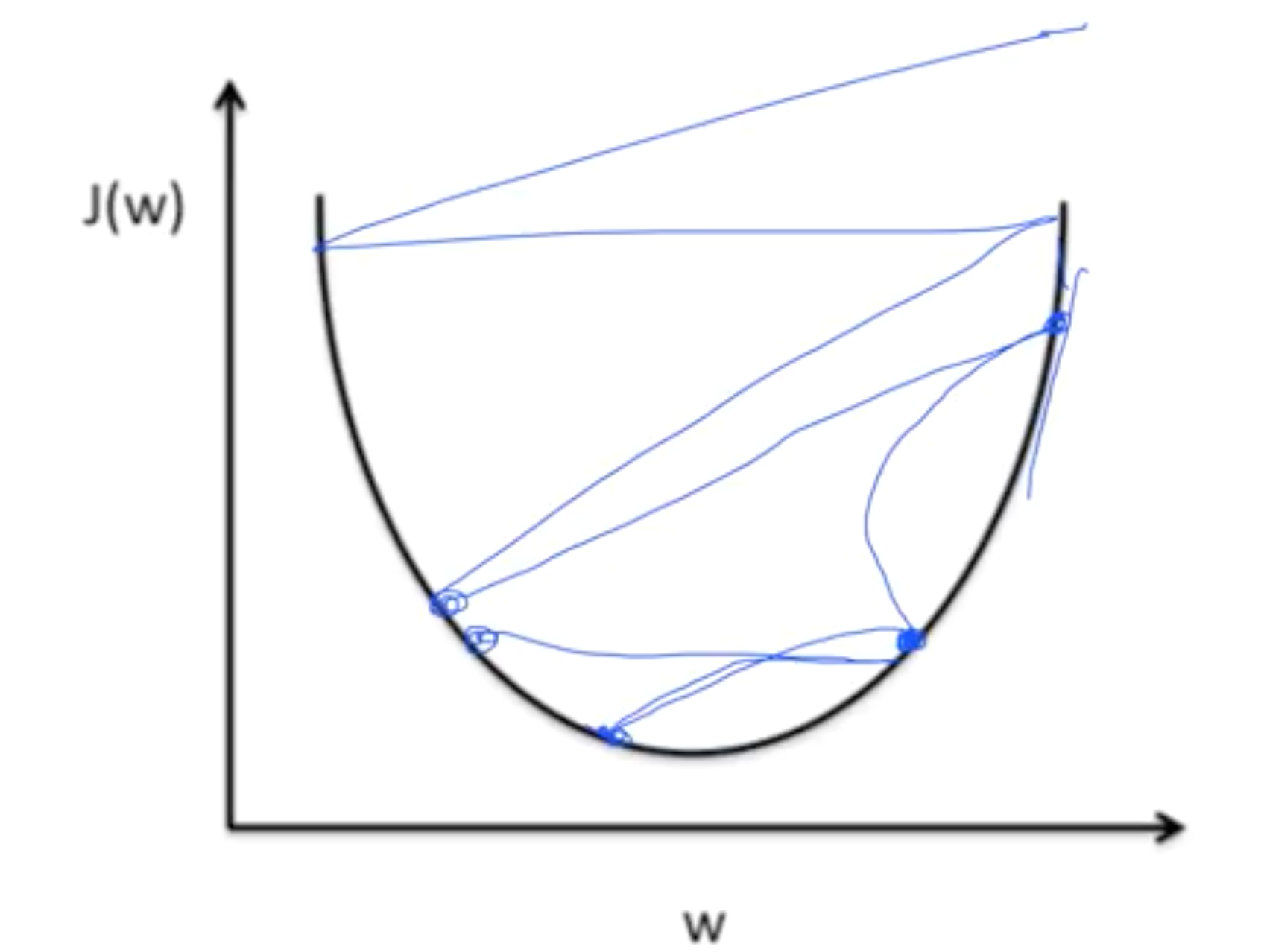
그림과 같이 step이 너무 클 때, 과하게 내려가다가 밖으로 튕겨나갈 수 있다.
반대로, 너무 작은 learning rate을 준다면 너무 오래 걸릴 수 있고, local minimum에서 stop할 가능성이 있다.
따라서, 적절한 learning rate을 찾기 위해서는 cost function을 관찰해야 한다. reasonable한 rate로 내려가는지 확인한다.
Sung Kim 교수님은 0.01에서 시작해, 발산이라면 낮추고, 너무 낮다면 높이라고 하셨다. 실험을 통해 적당한 값을 찾자.
Data Preprocessing for gradient descent
GDA를 사용할 때, data를 전처리해주어야하는 경우가 있다. data 값들 사이의 차이가 크면 GDA를 잘 적용할 수 없으므로 normalize해주어야 한다.
normalize 기법에는 여러 기법이 있는데, 여기서는 standardization을 소개한다.
Overfitting
: training set에 너무 잘 맞는 model을 형성해서, test set이나 real-world data에서는 오히려 정확도가 낮아지는 경우이다.
솔루션은 다음과 같다.
- More training Data
- Reduce number of features
- Regularization
이 중 regularization을 살펴보자. 이는 모델이 training set에서 너무 잘 적합하지 않도록 방지한다. 구분 경계를 구부리지 않고, 최대한 펴서 일반화시키기 위해 사용한다. 모델이 더 simple한 weight을 선택하도록 한다. Loss function 뒤에 다음과 같은 term을 더해주면 된다.
여기서 $\lambda$는 regularization strength로, hyperparameter이다. 상수항으로, regularization 정도를 부여한다.
만약 0이면 아예 regularization을 사용하지 않는 것이고 1이면 많이 주는 것이고, 0.01이면 크게 비중을 두지 않겠다는 것이다.
Training / Testing Dataset
모델 학습을 마치고, 모델 성능 검증을 하기 위해서는 test set을 따로 두어야 한다. training set으로 학습해 모델을 만들고, test set으로 검증하는 것이다.
보통 비율은 70:30으로 하는데, 상황에 맞게 다른 비율을 설정해도 된다.
training set에서 또 고려해야하는 것은 validation set이다. 이는 적절한 hyperparameters를 찾기 위해 필요하다. learnig rate이나 lambda가 이에 해당한다.
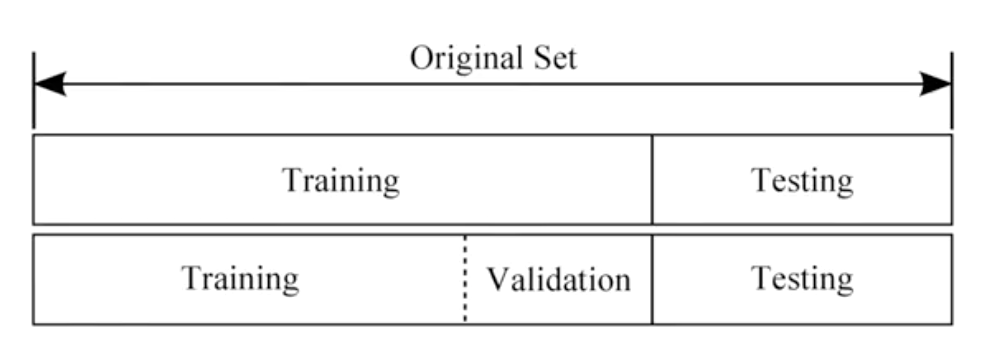
따라서, training set을 두 부분으로 나누어 적절한 hyperparameter를 찾는다.
Online Learning
100만개의 data가 있다면, 10만개씩 나누어 모델에 학습시키는 것이다. 이는 기존에 없던 데이터가 새로 들어왔을 때, 추가로 학습시킬 수 있어 유용하다.