머신러닝 프로젝트를 위한 기초 지식: 데이터 전처리, 앙상블, 교차 검증
기본적인 머신러닝 모델의 학습 방법
- 데이터를 탐색한 후 전처리하고
- 데이터 변수 등을 분석하여 전체 훈련용, 테스트용 데이터 셋을 구성한 다음
- 해결하고자 하는 문제에 맞는 알고리즘을 선택하여 모델을 만든 후
- 훈련용 데이터 셋으로 모델을 학습시키고
- k-folds 교차검증 및 테스트용 데이터 셋 으로 모델 간 검증을 진행하고
- 최고의 성능을 보이는 모델을 최종 배치한다.
출처: https://sacko.tistory.com/38 [데이터 분석하는 문과생, 싸코]
데이터 전처리
결측치 처리
- 결측치 삭제
- 데이터 최빈값 삽입
- 데이터 평균값 삽입
범주형 변수 (categorical data) 처리
문자형 값을 숫자형으로 변환하는 방법이다.
- 데이터 인코딩
- 레이블 인코딩: 월,화,수 —> 1,2,3
- Data Binding: 연속형 데이터를 구간으로 나누어 범주화
Feature Scaling
단위가 서로 다른 경우, 값이 큰 feature가 결과값에 더 영향을 줄 수 있으므로 데이터 전처리가 필요하다.
- Min-Max Normalization
- Standardization
PCA (주성분분석)
- 차원 축소; 고차원의 데이터를 저차원의 데이터로 변환함
- Feature Extraction; 적은 수의 특징만으로 특정 현상을 설명하려 할 때 사용
- 데이터 집합 내에 존재하는 각 데이터의 차이를 가장 잘 나타내 주는 요소를 찾아내는 방법
앙상블 모델 비교
앙상블 기법
- 여러개의 weak learners 를 이용해 최적의 답을 찾아내는 기법
- 예측기가 가능한 서로 독립적일 때 최고의 성능을 발휘함
배깅(Bootstrap AGGregatING, Bagging)
테스트 데이터 샘플링(Bootstrap) 통해 여러개의 테스트 데이터를 만들고, 각 테스트 데이터를 이용해 여러개의 weak learner 를 만든다. 최종적으로 각 learner 의 예측결과를 평균내서 종합(aggregate)한다.
부스팅(Boosting)
부트스트래핑된 테스트 데이터로 여러개의 weak learner 들을 순차적으로(iterative) 만드는데, i번째 learner 는 i-1 번째 learner 가 잘못 예측한 데이터에 가중치를 좀 더 주어서(boosting) 학습한다. 최종적으로 마지막에 생성된 learner 를 이용하여 예측한다.
결국, 틀린 부분에 가중치를 더하면서 진행하는 알고리즘이다.
Gradient Boosting의 문제점
- 느리다
- Overfitting 이슈
Random Forest
- decision tree 기반
- training set으로 부터 무작위로 각기 다른 subset을 만들어 decision tree를 학습 시키고, 모든 개별 트리의 예측을 구한다. 그리고 가장 많이 선택된 class를 결과값으로 정한다.
- 여러개의 decision tree classifier 생성, 각자의 방식으로 데이터를 샘플링해 개별적으로 학습 후 voting을 통해 데이터에 대한 예측 수행
XGBoost
- Boosting 과정에서 가중치를 줄 때, 경사 하강법 알고리즘의 단점을 보완했음
- 과적합 방지가 가능한 규제가 포함되어 있음
- 분류, 회기 둘 다 가능
- early stopping 제공
LightGBM
- Xgboost의 학습시간은 여전히 느렸음
- 대용량의 데이터 처리가 가능하고, 다른 모델보다 더 작은 메모리를 사용, 빠름
- 너무 적은 수의 데이터를 사용하면 과적합 문제 발생
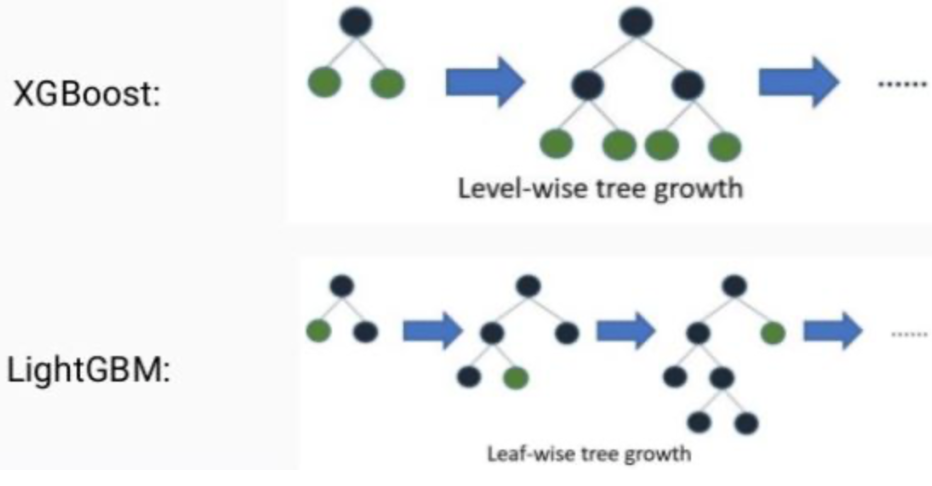
- XGBoost와 달리 leaf wise (리프 중심) 트리 분할 사용 균형을 맞추지 않고 리프 노드를 지속적으로 분할하면서 진행
- XGBoost는 level wise (균형 트리) 분할 사용했음 균형을 잡아주기 위해 tree의 depth가 줄어들지만, 균형을 잡아주기 위한 연산이 추가됨
Hard-voting v.s. Soft-voting
Hard-voting
앙상블 기법에서 각 분류기의 예측을 모아 다수결, majority로 클래스를 결정내리는 방법
Soft-voting
같은 class로 예측한 결과들의 probability를 모두 더하고 평균을 내 비교, probability가 더 높은 것을 채택!
우승자에 따르면, 이번 competition 실험 evaluation metric이 log-loss였기 때문에 probability를 평균내는 방식의 성능이 좋았다고 한다.
교차 검증
Hyper parameter
튜닝 옵션, 연구자나 기술자들이 직접 세팅해야 하는 설정
교차 검증의 필요성
- 고정된 학습 데이터와 테스트 테이터로 평가하게 되면, 주어진 데이터에 대해서만 최적의 성능을 발휘하도록 편향된다!
- Overfitting을 방지하고 정확도를 높이기 위해 사용됨
- test set 외에 별도의 validation set을 두어 평가함
K-fold Cross-validation
- K개의 데이터 폴드 세트를 구성해 K번 만큼 각 세트에 대해 학습과 평가를 수행
- fix random seed for ‘reproducibility’
- 우승자 코드에서 seed값을 임의로 부여해 의문이었는데, 찾아보니 재생산성을 위해 보통 시드값을 지정한다고 한다.